
Power Query: Blog List – Part 4
20 December 2023
Welcome to our Power Query blog. I would like to get a list of all the Power Query blogs I have posted. Today, I improve the query to extract data from all pages by extracting the last page number from the data.
I started writing this blog series way back in 2016:
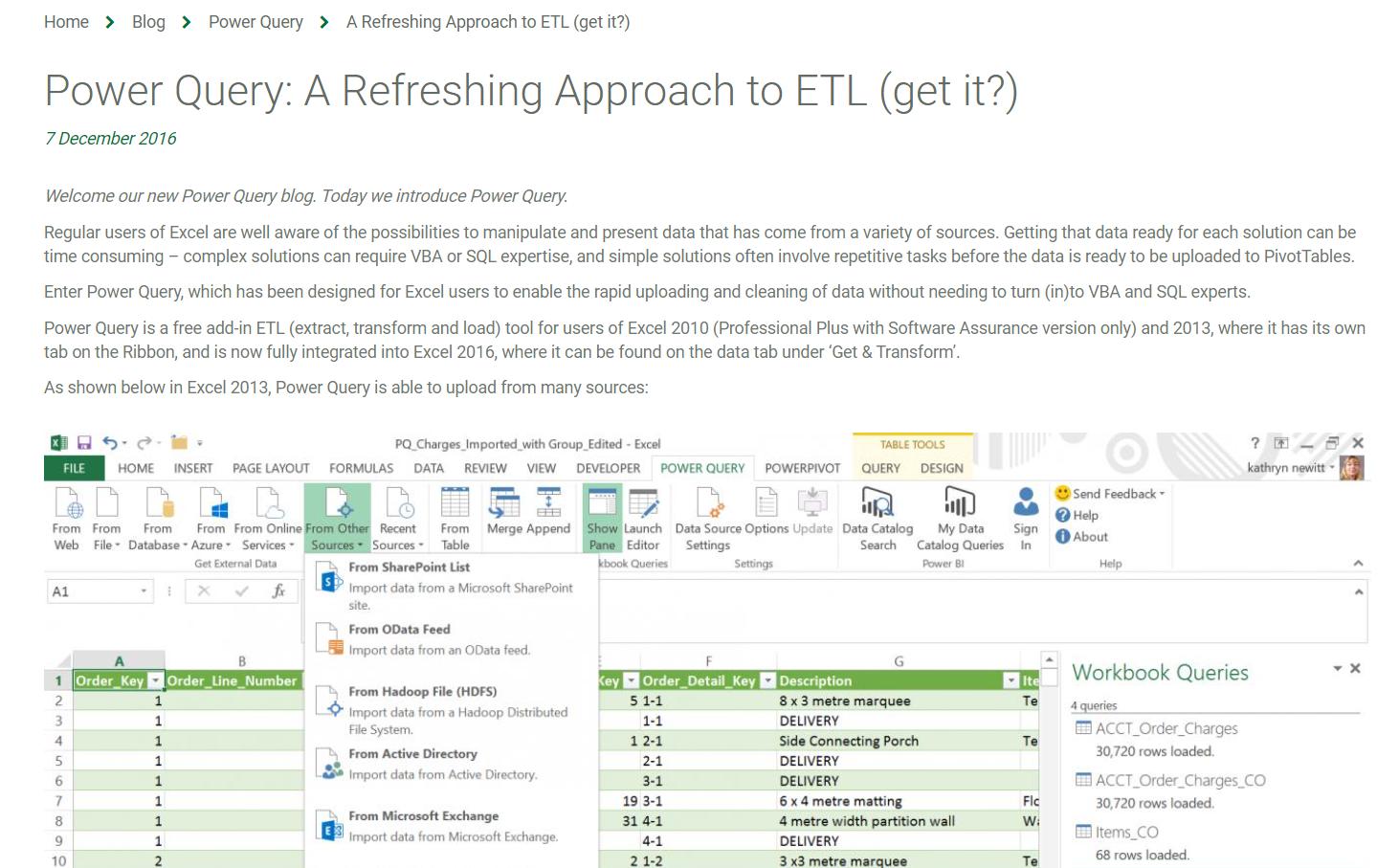
There have been many developments since then, some of which I have reported upon. Since I am going to revisit more of the areas that have been improved, I am going to start with a reminder of what we have covered so far. In order to do this, I am going to use Power Query in Power BI, since there are some functions that will help me to access web data, which are not yet recognised in Power Query (Get & Transform) in Excel.
In Part 1, I noted that to get a full list, I am going to need several pages:
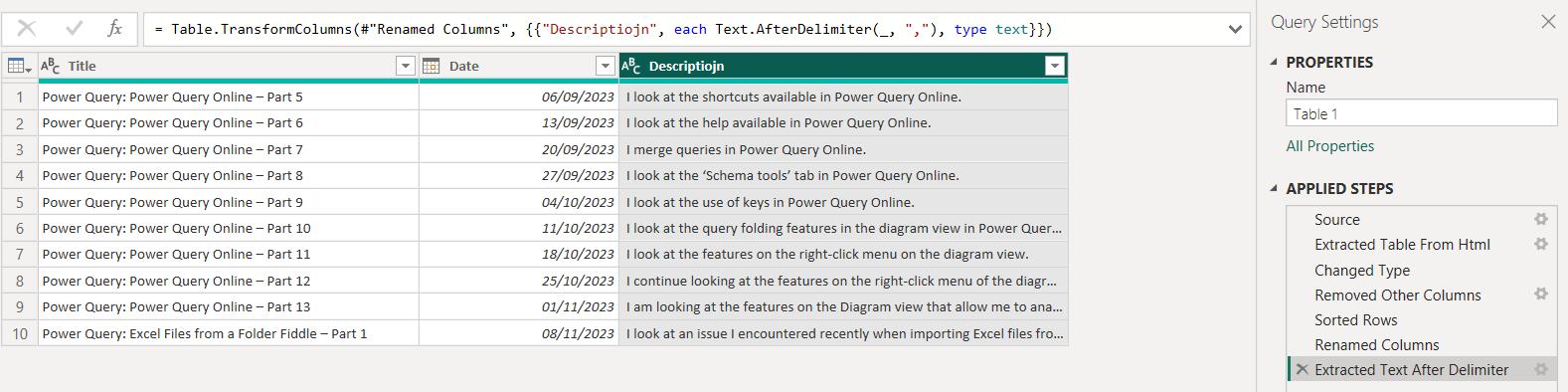
I extracted and tidied up the data for the first page:
In Part 2, I changed the Source step of my query to accept a parameter P_PageNumber, which allows me to get the data from a specific page. I used the following M code:
= Web.BrowserContents("https://www.sumproduct.com/blog/power-query-blogs?page="&Number.ToText(P_PageNumber))
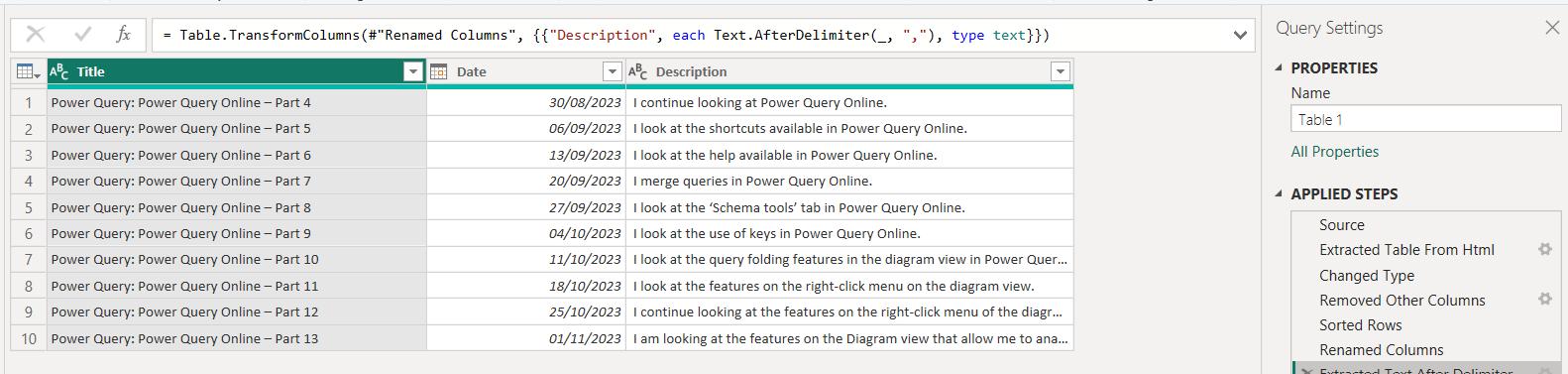
I checked that this still gave the same results for the query:
Last week, I converted this query into a function, and generated a list of page numbers to concatenate my data:
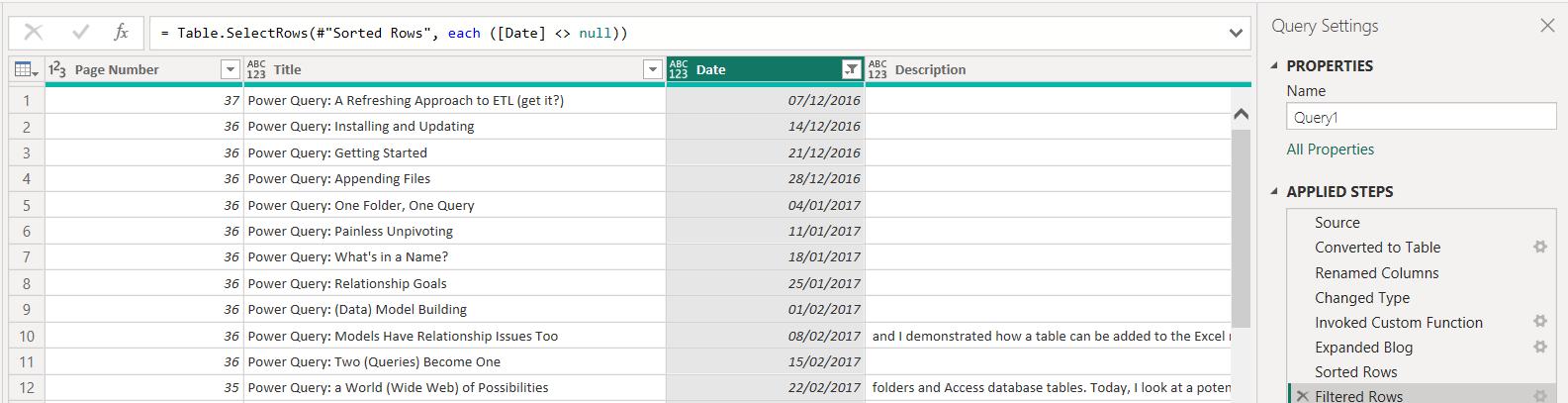
This time, I start by going back to the function behind the query to review the step that I used to remove repetitive data from Description:
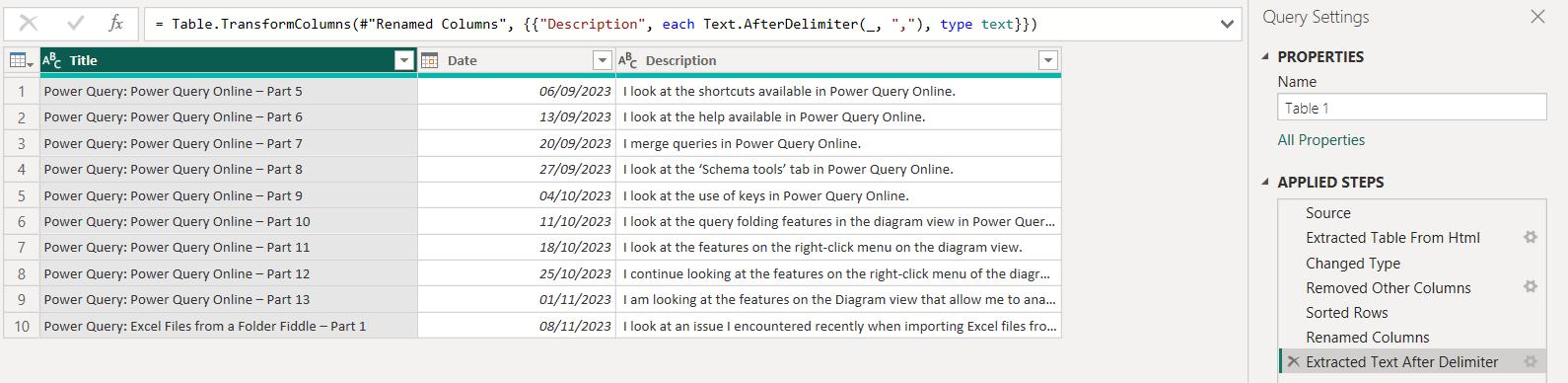
I remove the final step to see what is happening to the data in Description on the earlier rows in my combined query:
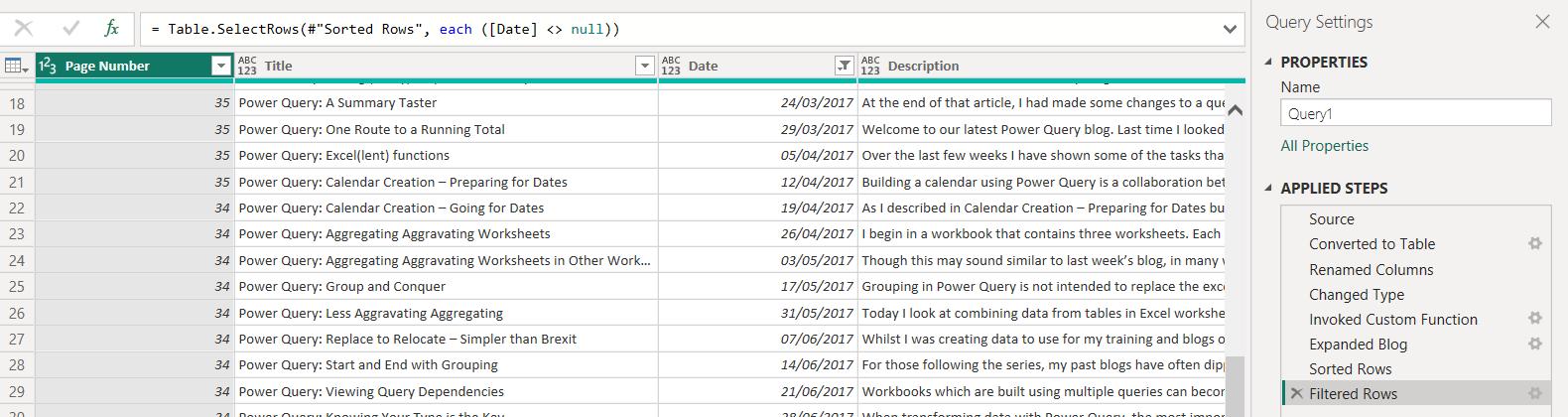
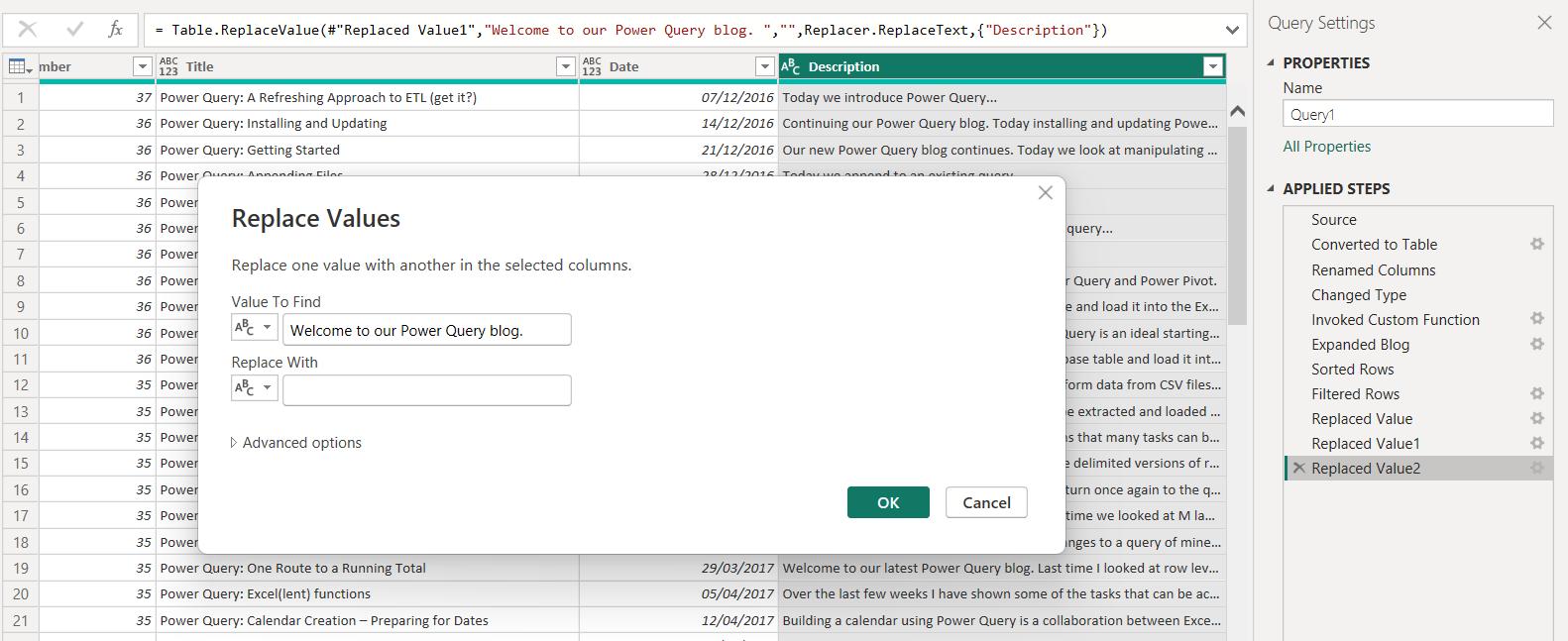
Clearly, I haven’t always been as consistent! A better approach would be to replace any repetitive text with empty space. I can do this in the combined query, currently called Query1:
I could improve my query further by removing the hard coded page number from my list generation and instead, extract the number of pages from the data. To do this, I begin by making a Duplicate of Table1:
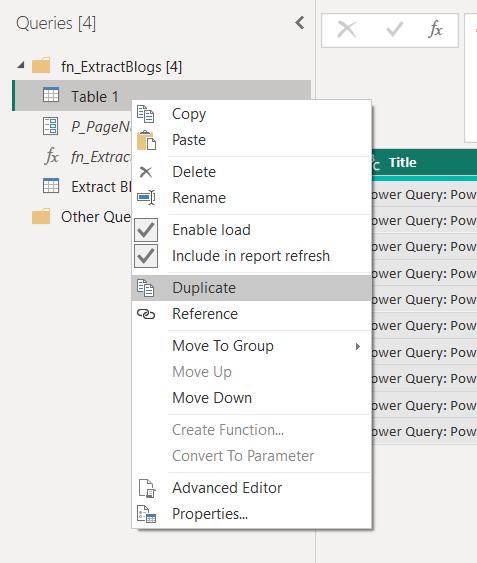
I (optimistically) call my new query P_LastPage. I only want to keep the Source step:
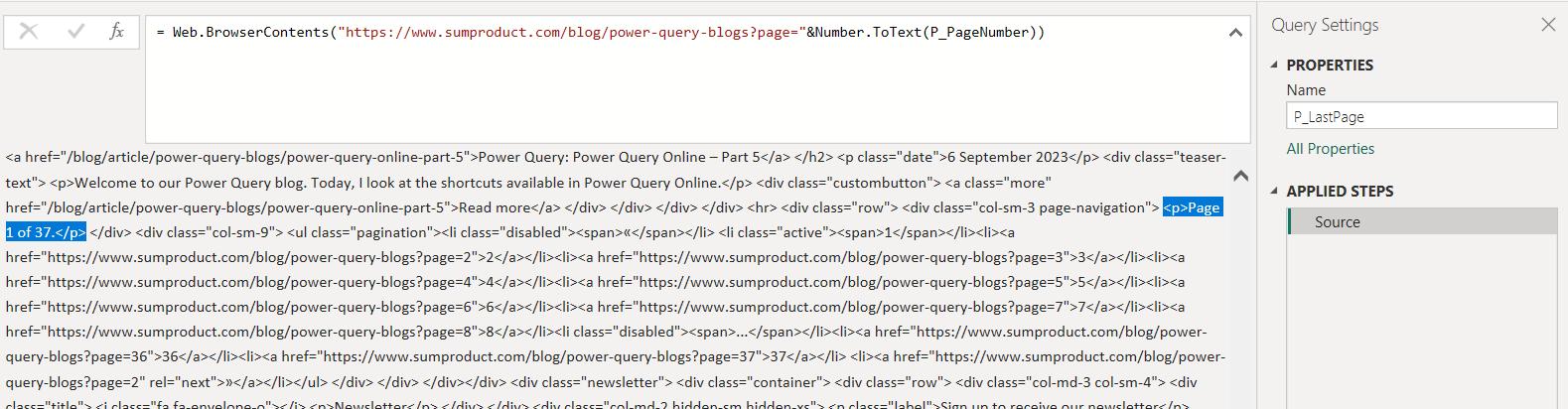
I have highlighted the text I need, and I need the total number of pages from this:
<p>Page 1 of 37.</p>
Now, I need a way of extracting the number I want. My options at the moment appear to be limited:
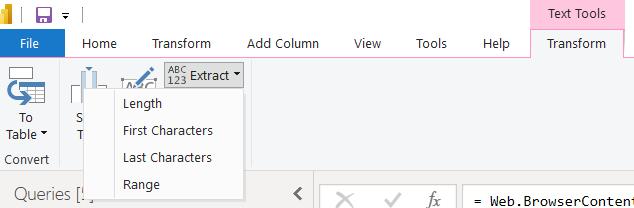
I want to look for text before the delimiter “<p>Page 1 of”, and after the delimiter “.</p>”. To access this functionality, I need to convert the text to a Table:
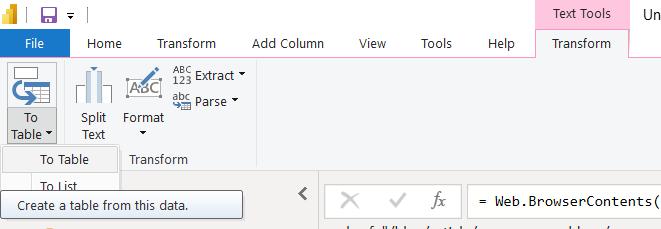
This makes the data harder to see, but I know the delimiters I need to use:

On the Transform tab, I choose to Extract ‘Text Between Delimiters’:
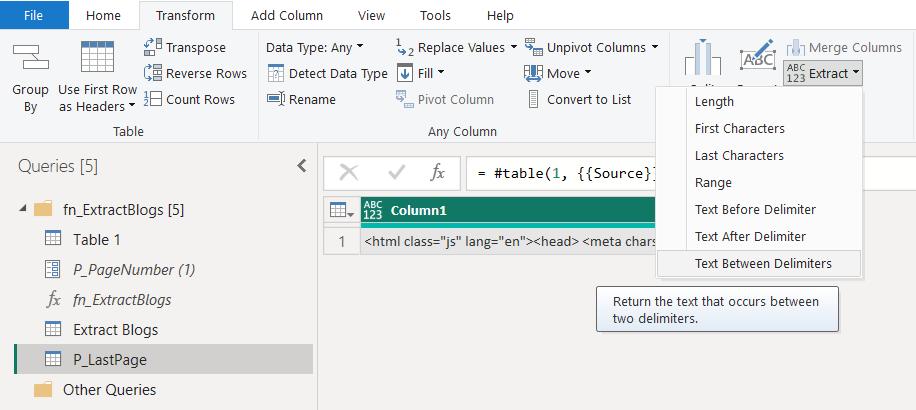
I enter the required delimiters in the dialog:
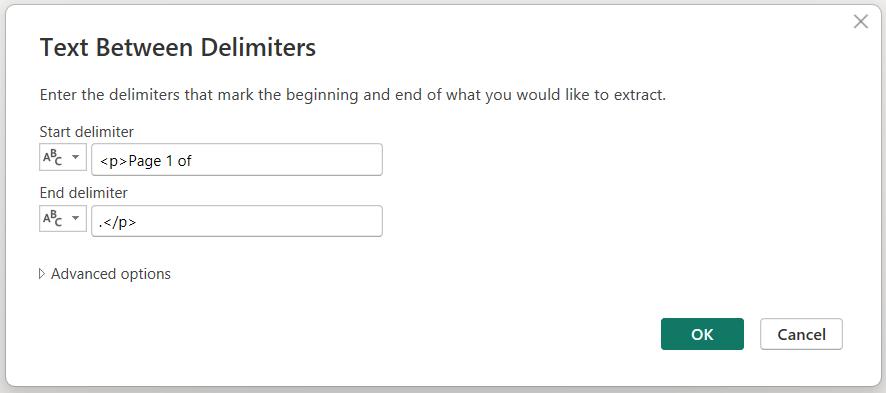
This gives me the data I need, and I change the datatype to ‘Whole Number’ to allow me to use it in the list generation.

Now, I can right-click on and ‘Drill Down’ into this value:
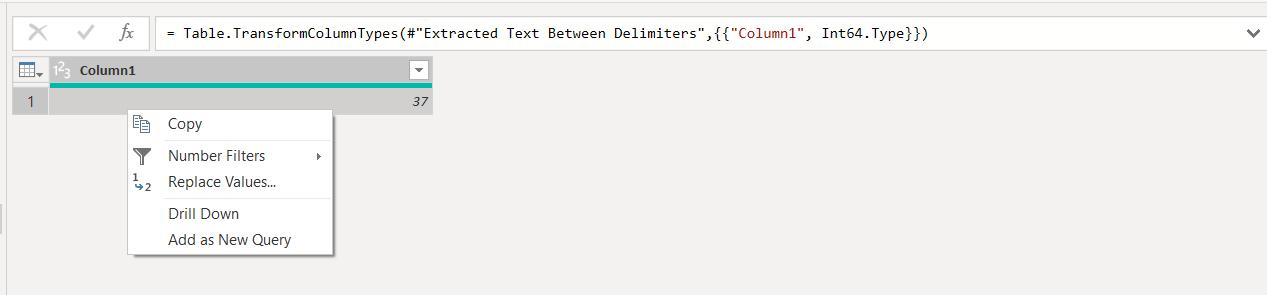
This gives me my parameter P_LastPage:

I have renamed my main query to Extract Blogs. I need to change the current Source step:
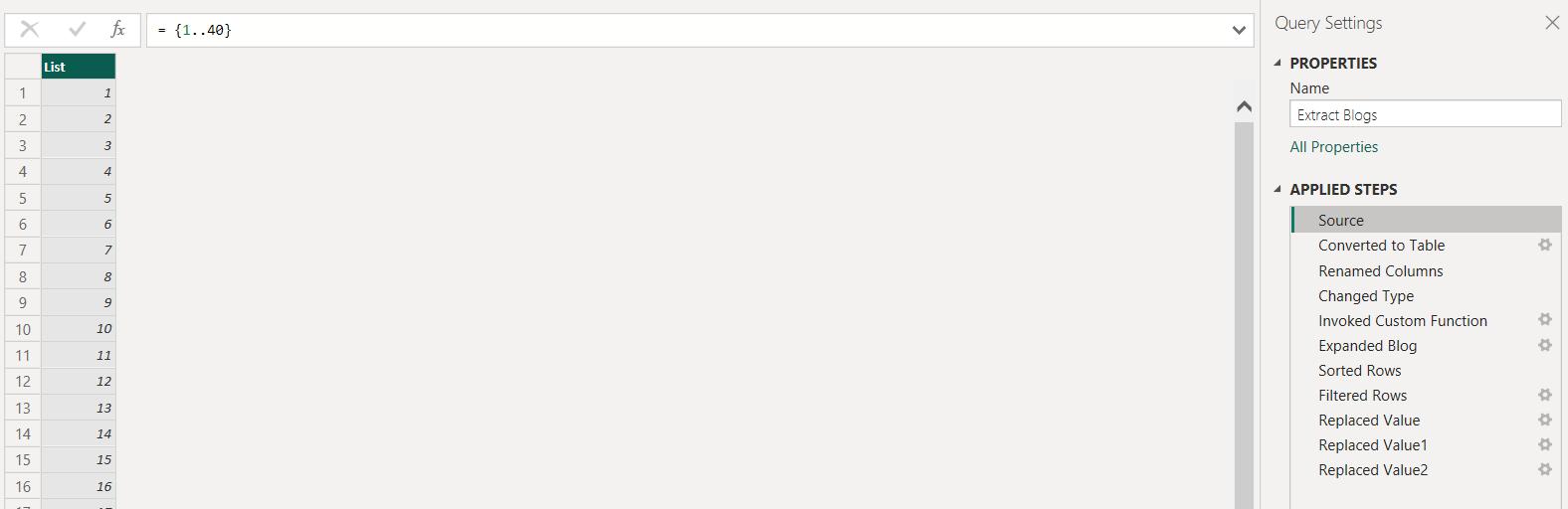
Instead of the hard-coded value 40, I use P_LastPage:
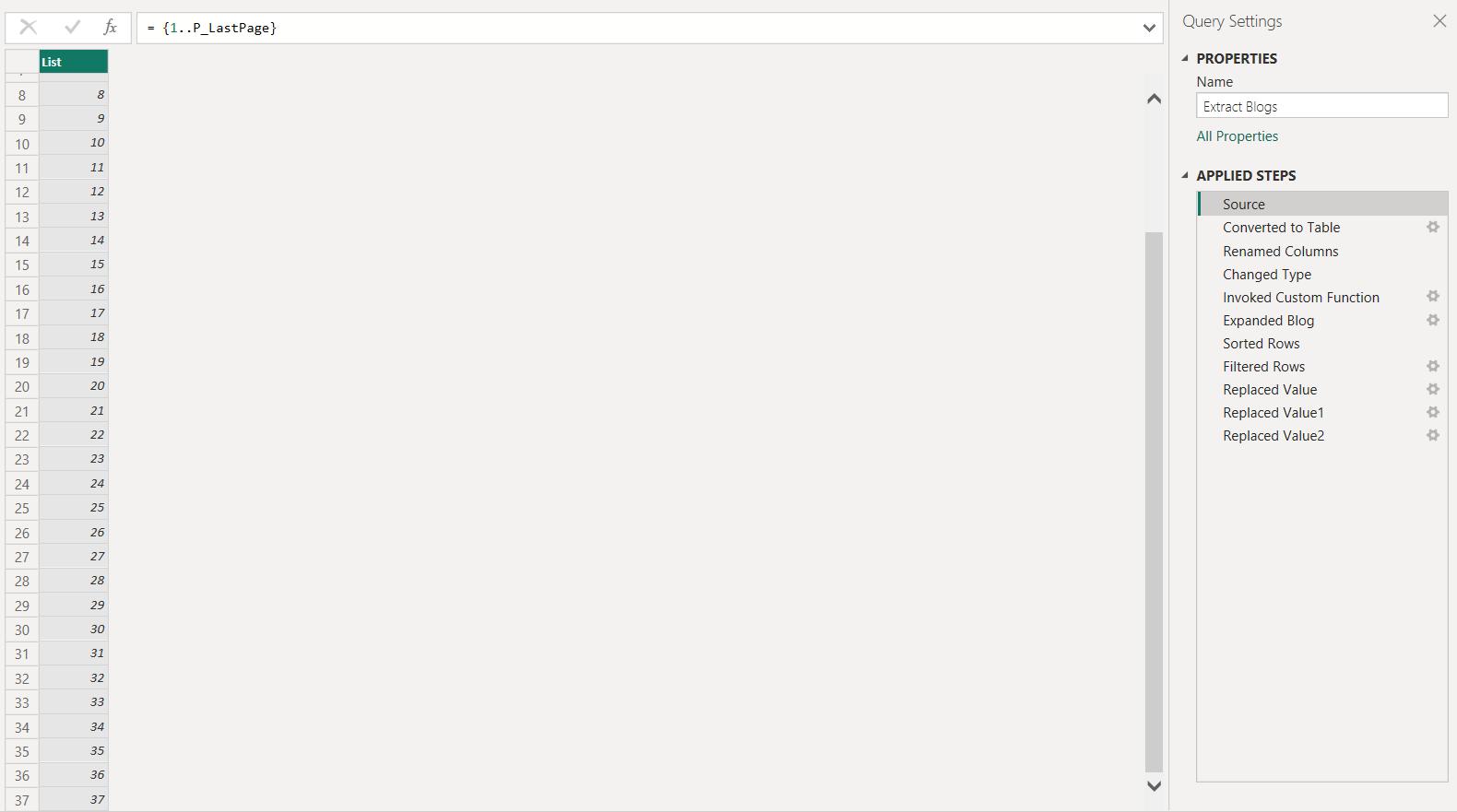
Now I have the exact number of pages, I no longer need the ‘Filtered Rows’ step which was removing empty rows; therefore, I delete it and ignore warnings about deleting an intermediate step:

My query is ready to load, so I select all my data and ‘Detect Datatypes’ from the Transform tab:
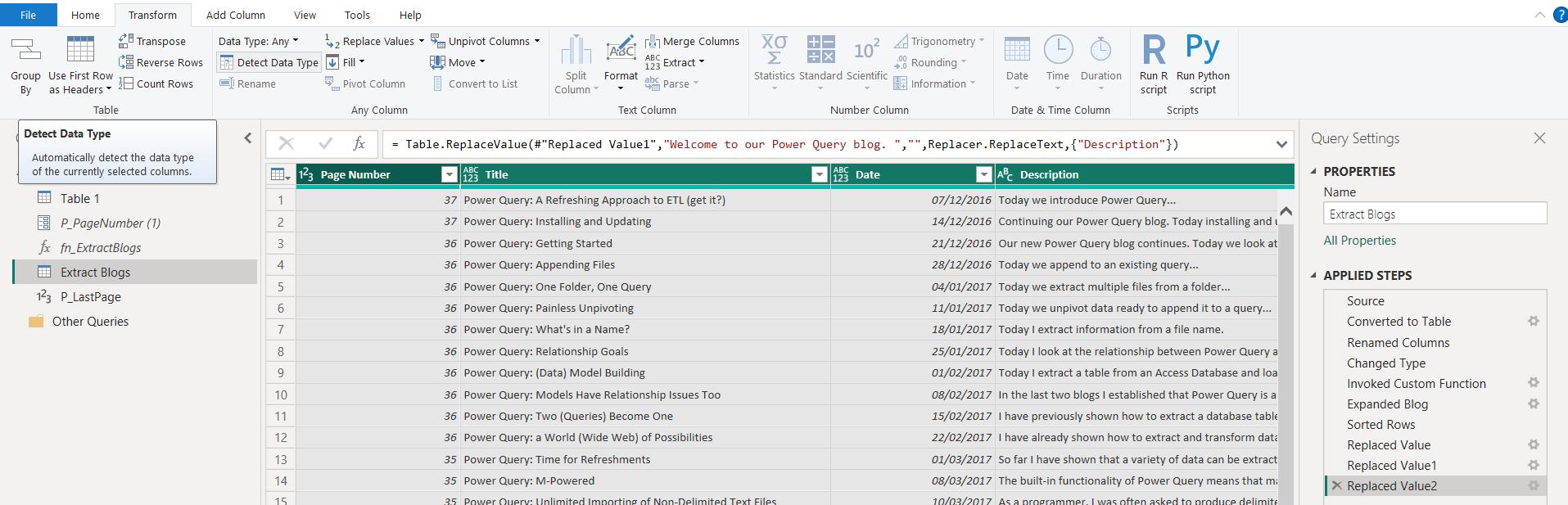
Now the list is complete:
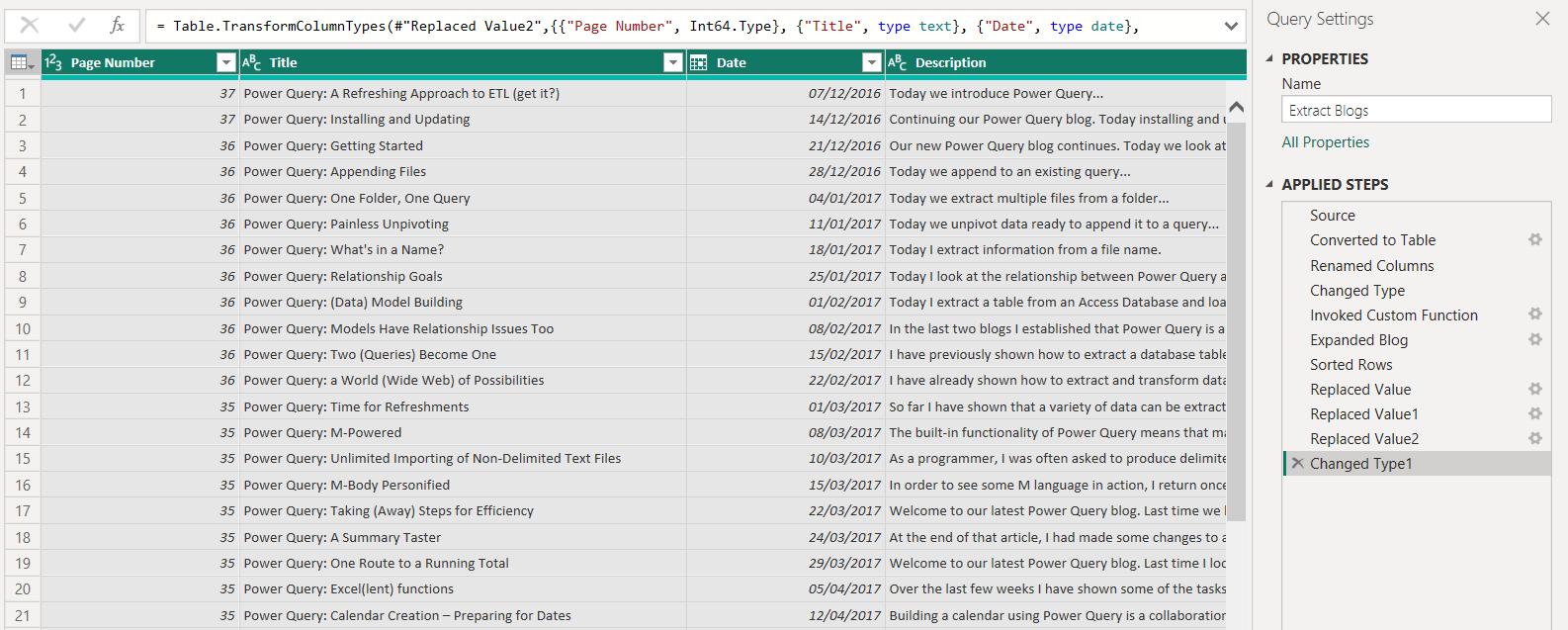
Next time, I will look at why this cannot be achieved in Power Query for Excel.
Come back next time for more ways to use Power Query!