
Power Query: Making Your Mark(up) Part 6
19 February 2025
Extensible Markup Language (XML) is a markup language which can be utilised by multiple platforms and also uses text which can be read. It is commonly used to store data which is used by more than one platform. Accounting data may be stored in this way when it is accessed by more than one accounting software system. The example I am using today comes is on GitHub, and may be accessed here if you wish to follow along. The data represents DNA data from a crime scene sample!
In Part 4, I accessed the file from the web, using the ‘From Web’ connector in the ‘Get Data’ dropdown. I imported two [2] queries:
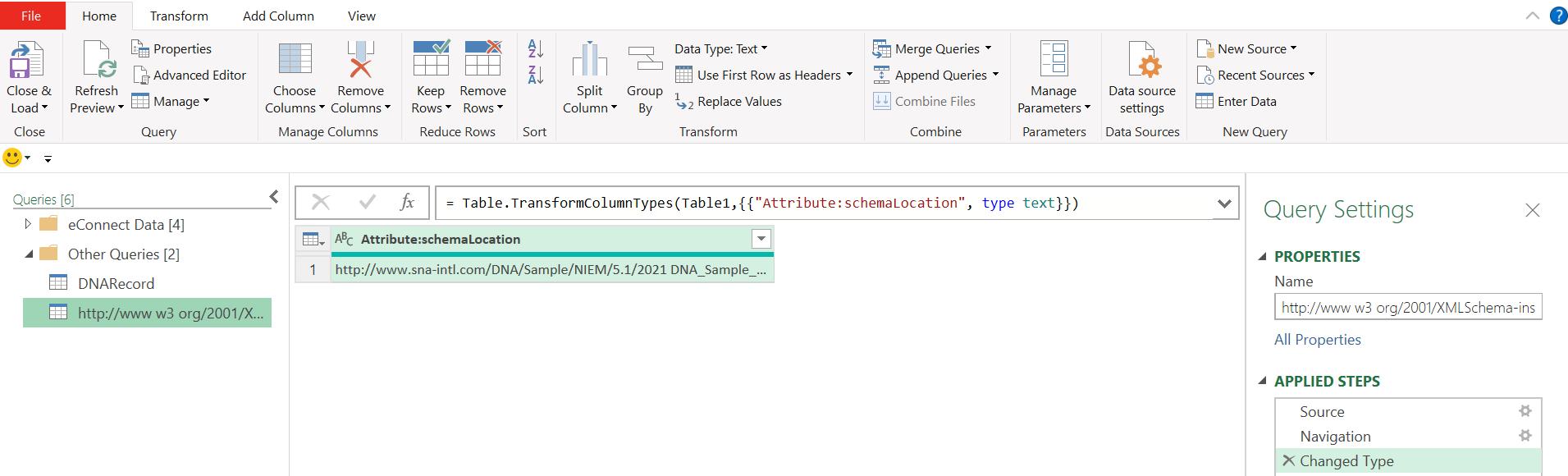
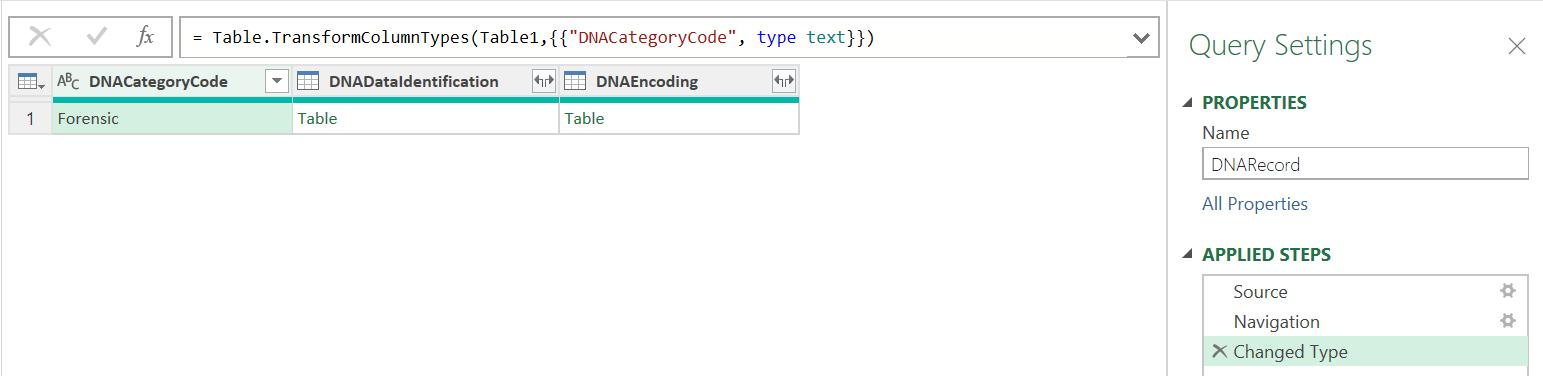
The catchily-named http://www w3 org/2001/XMLSchema-instance contains information about the original URL. I am more interested in the DNARecord query:
Last week, I examined the Source step:

I found that the only way to split this nested step was to enter the steps separately in the ‘Advanced Editor’, accessed from the Home tab.
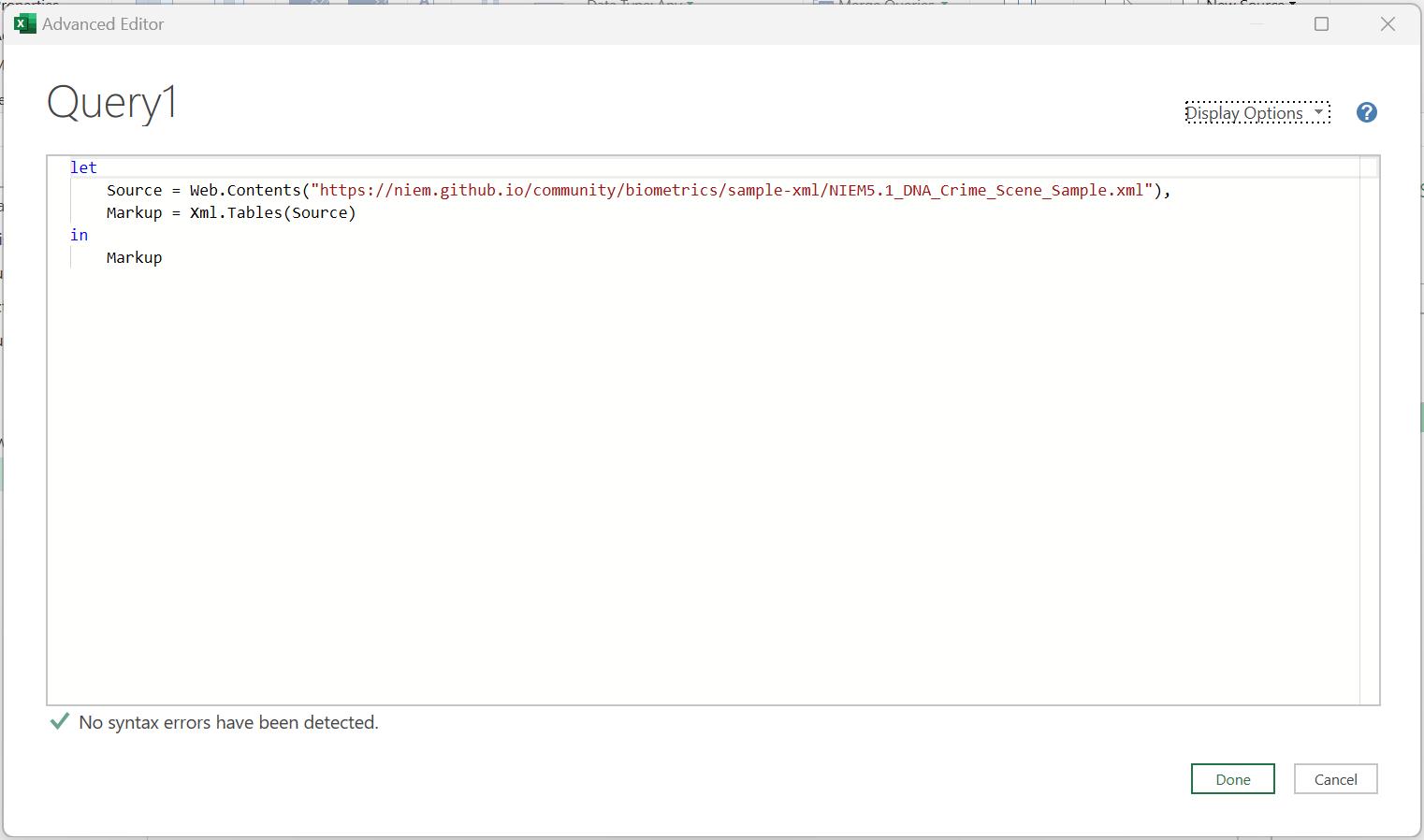
In this way , I had the two steps in the ‘Applied Steps’ pane:
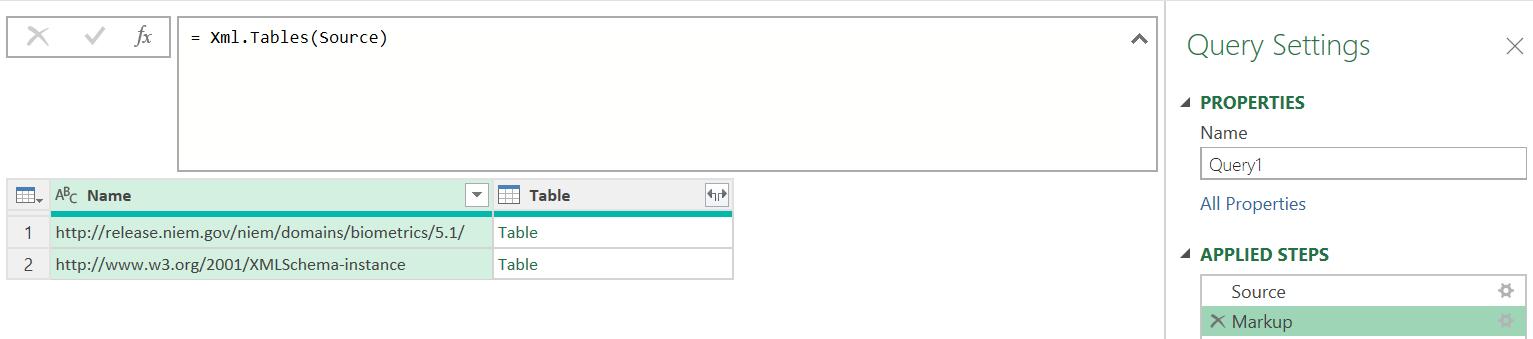
This time, I will extract the data from the DNARecord query. Going back to this query, I may examine the data in the columns:

If I click in the white space next to each ‘Table’ I can see the associated data in column DNADataidentification and DNAEncoding respectively:
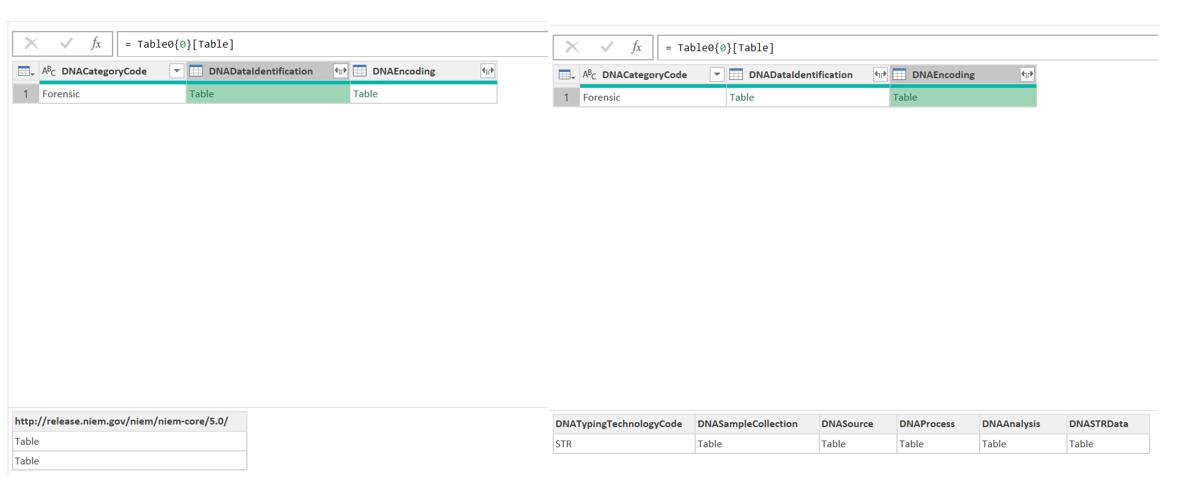
The data has not been flattened in the same way as the data I extracted from a file in Part 1. If I simply expand all the tables I will have a mess of data! I will look at different ways of splitting up the data in order to make sense of it. I begin by creating a duplicate copy of DNARecord, and I rename the original query DNARecord Identification and the copy as DNARecord DNA Tables. This will allow me to split the header identification data from the tables, which appear to be subsets of data associated with the identification data.
In DNARecord Identification, I choose to keep the first two [2] columns.
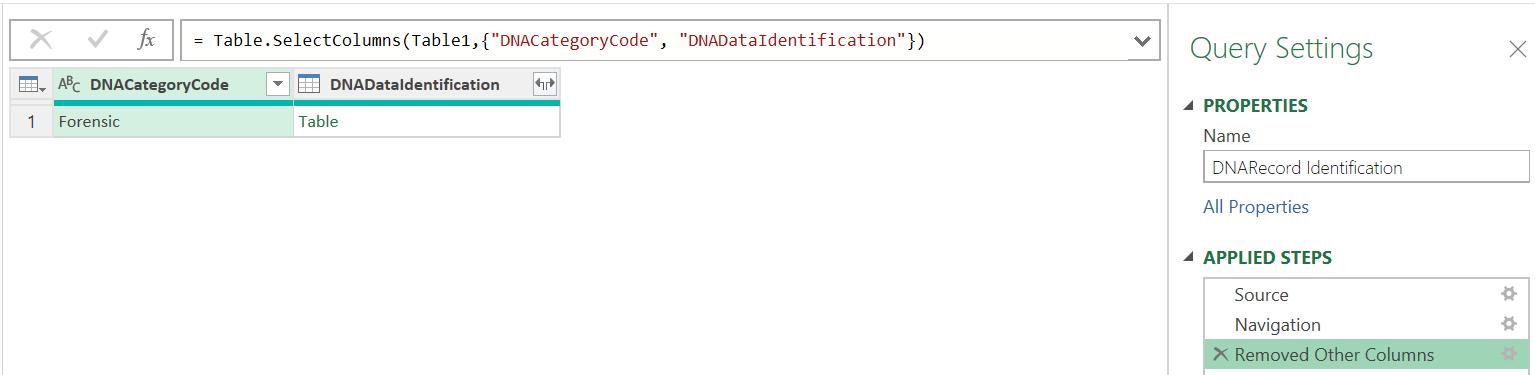
I may then expand the nested ‘Table’ twice to extract the data:
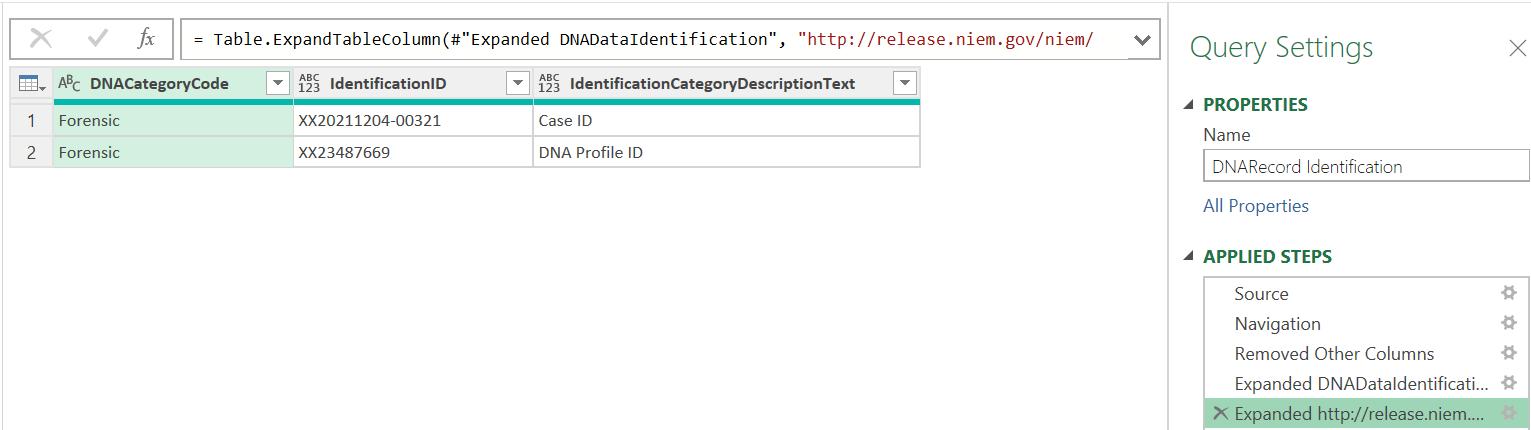
I have now extracted the header information. In the DNARecord DNA Tables query, I begin with the same approach, keeping the DNAEncoding column this time:
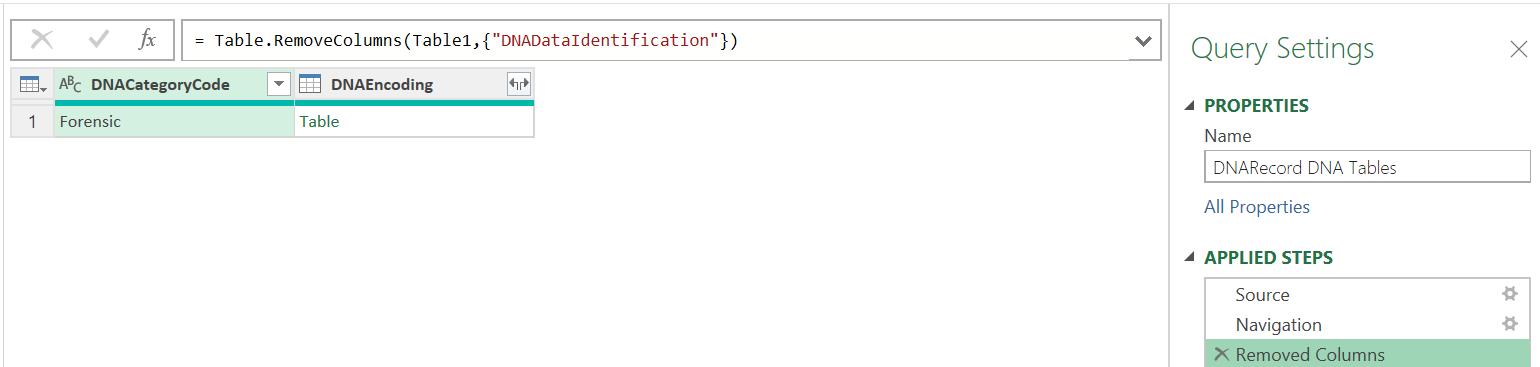
However, when I expand the ‘Table’ I have five [5] more columns of ‘Table’s to deal with:
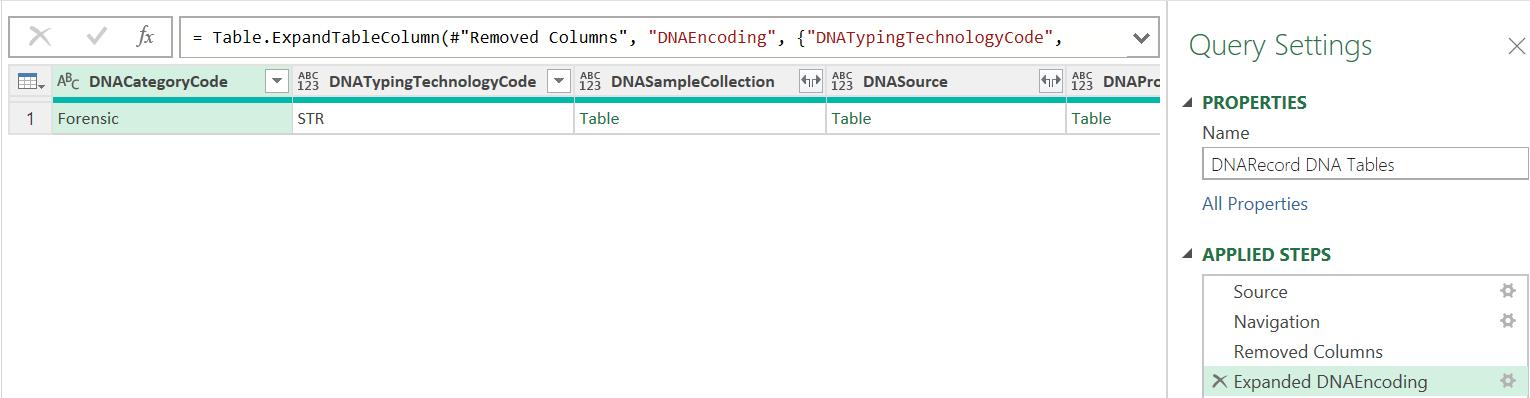
I could make more duplicate queries but this time I choose a different approach. I select the DNASampleCollection column and right-click to ‘Add as New Query’:
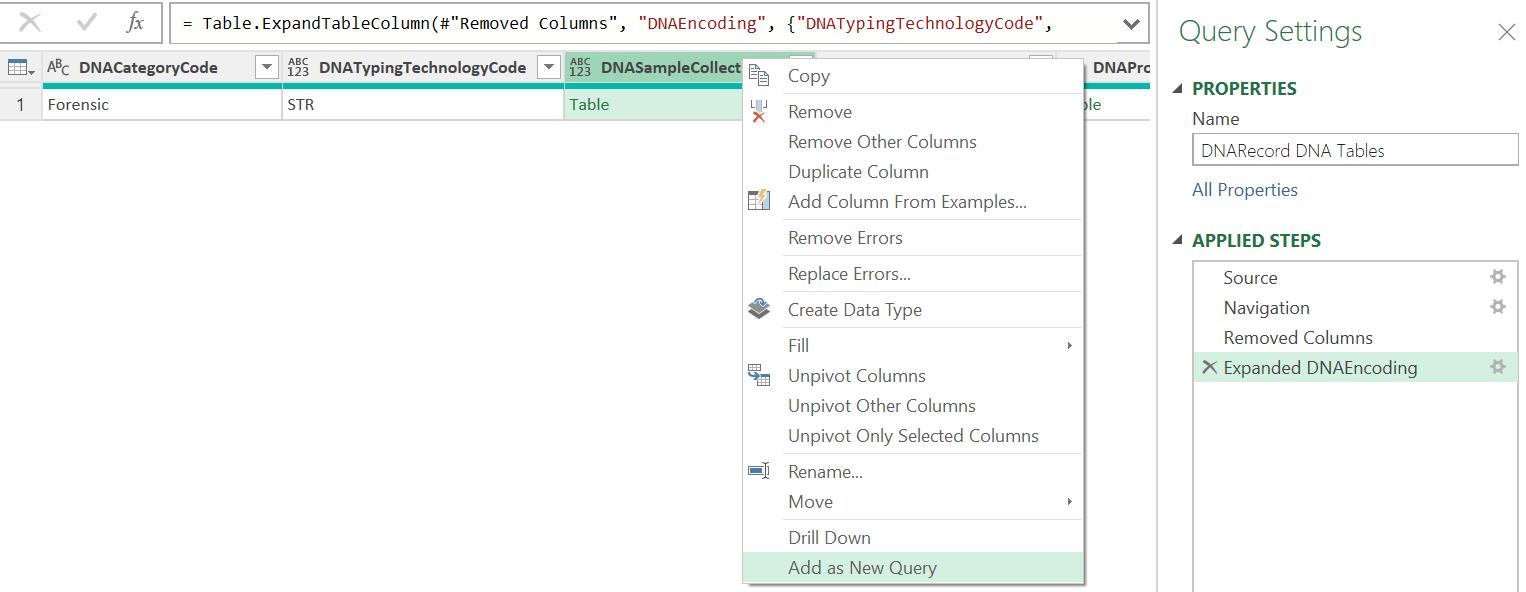
This creates a new query called DNASampleCollection:
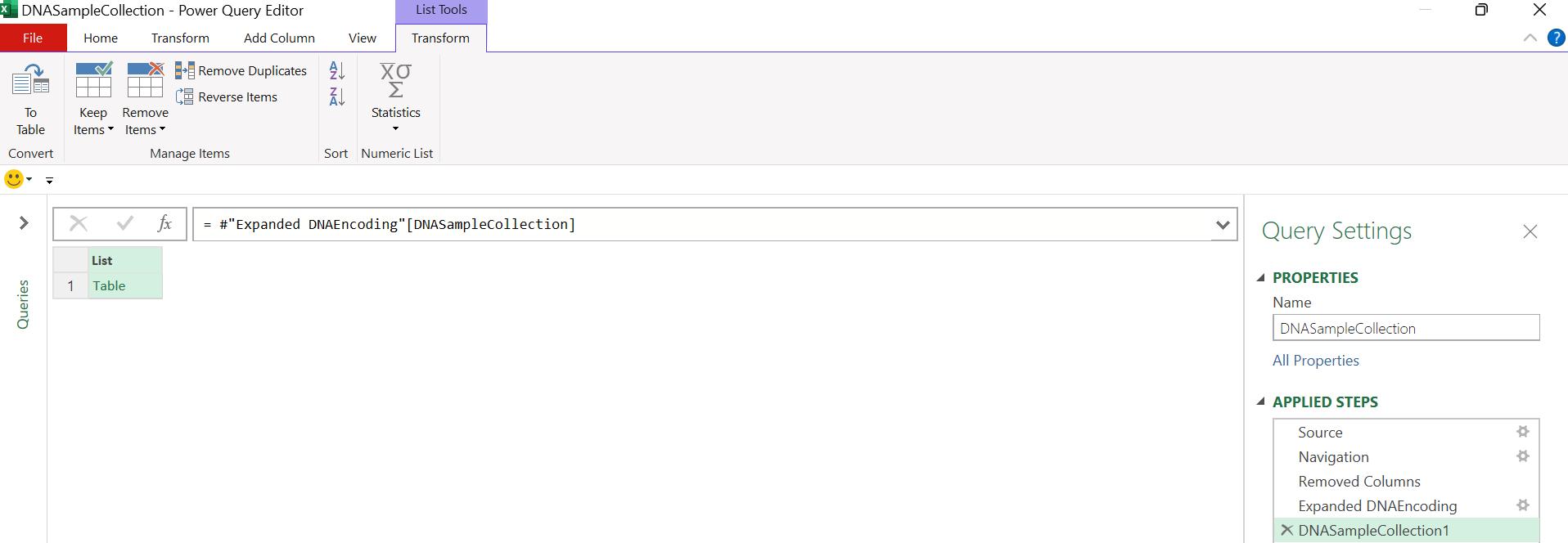
I convert the list ‘To Table’ and repeatedly expand the nested ‘Table’s to extract the data:
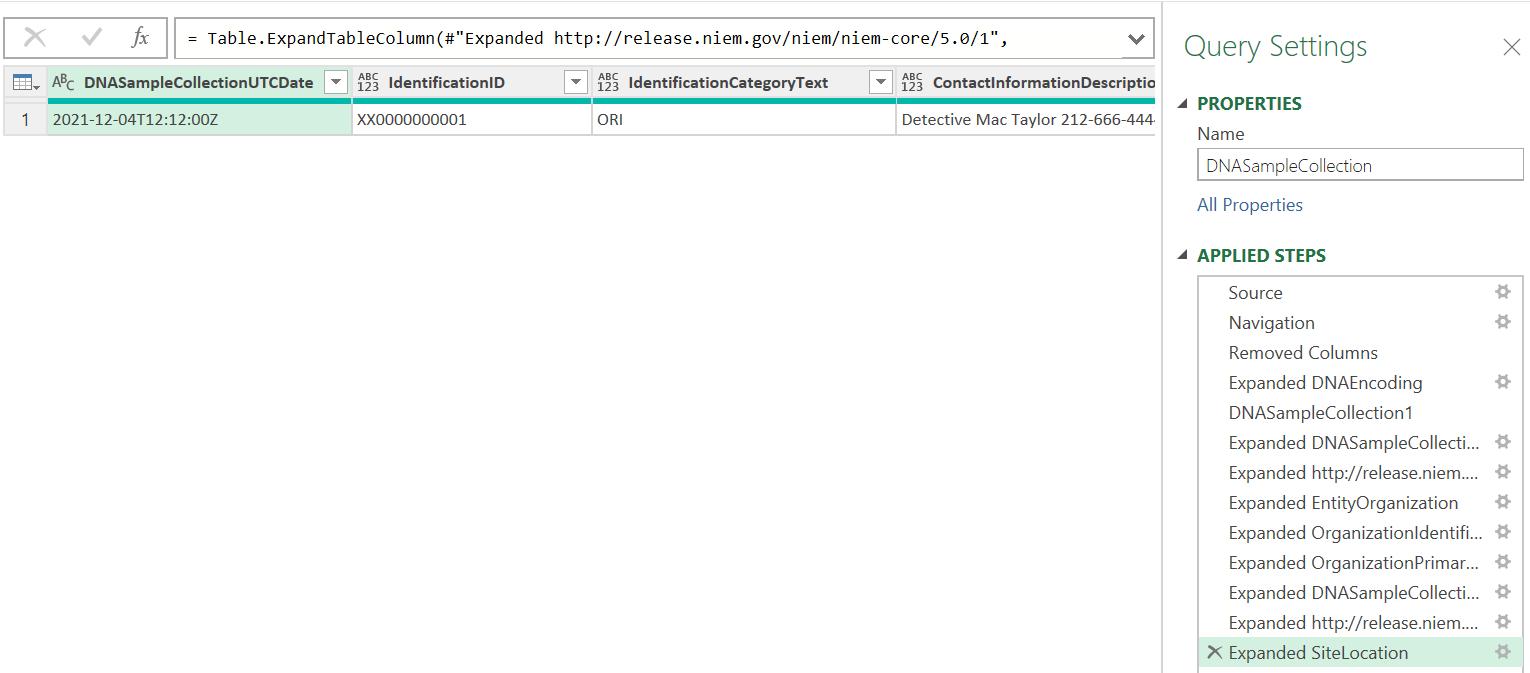
I repeat this process for the other columns in DNARecord DNA Tables, creating four [4] more new queries and expanding any nested ‘Table’s to flatten the data:

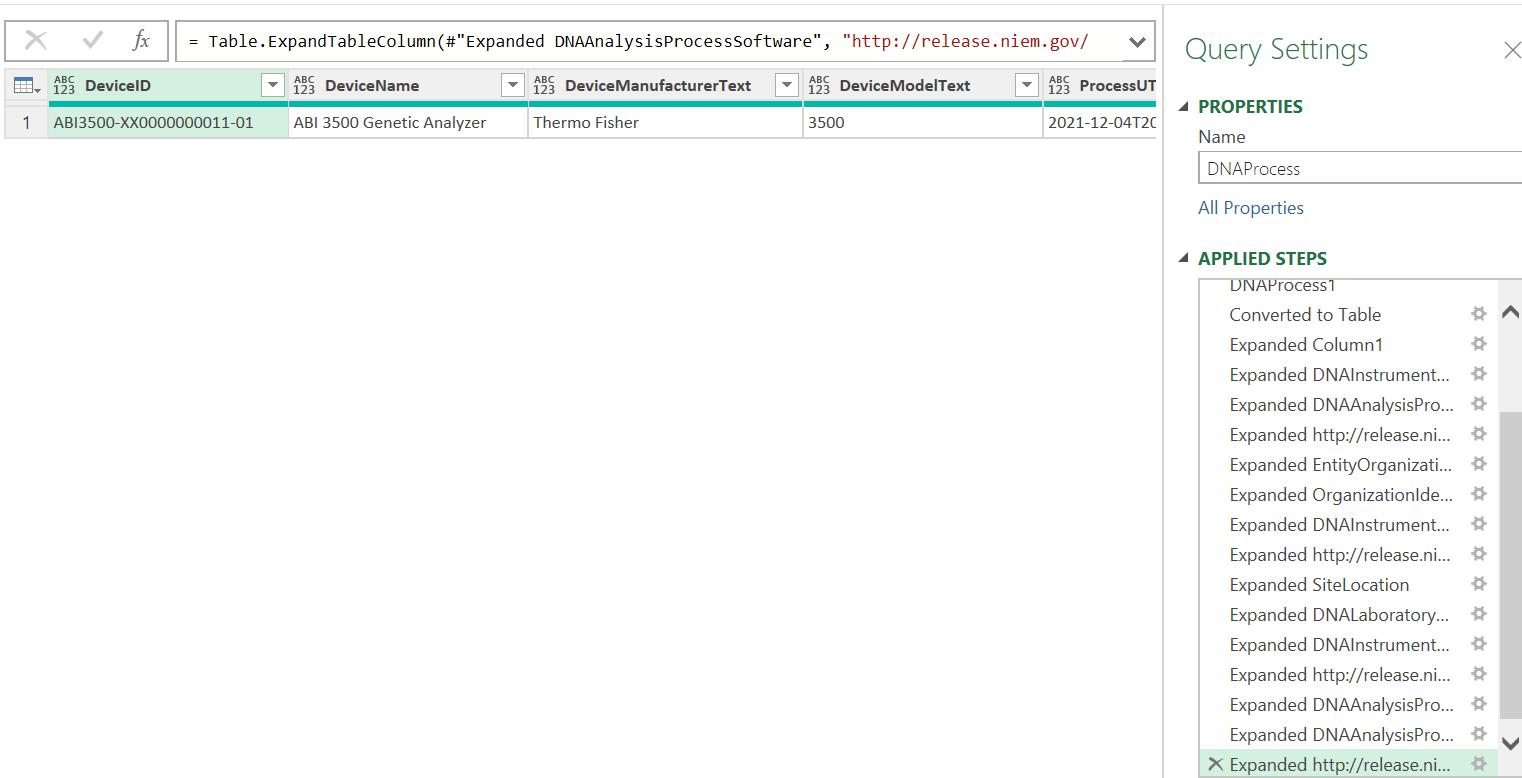

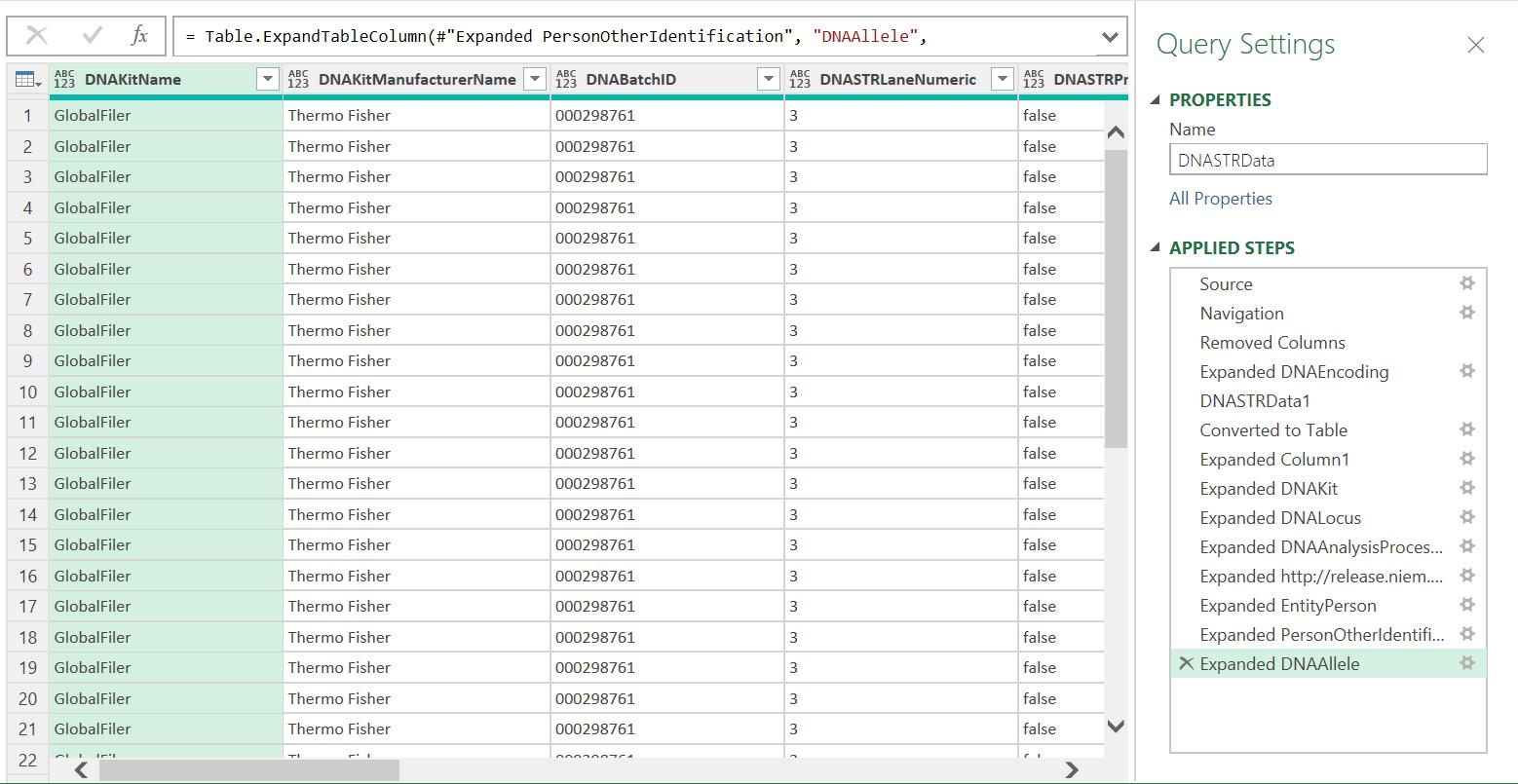
Now I have unpacked the data, it is ready to use in reports or dashboards.
Come back next time for more ways to use Power Query!