
Power Query: Sub Texting
20 June 2018
Welcome to our Power Query blog. Following on from last week’s blog, this week I look at some useful extraction Text() functions in M.
In my final look at text functions, I will describe some Text() functions that extract part of my string. In this way, I can create useful new columns that can help me to link my data to other tables. As I did for Boolean and transforming functions, I will give an example for each one.
Text.Middle
Text.Middle(text as nullable text, start as number, optional count as nullable number) as nullable text
Returns count characters, or through the end of text; at the offset start.
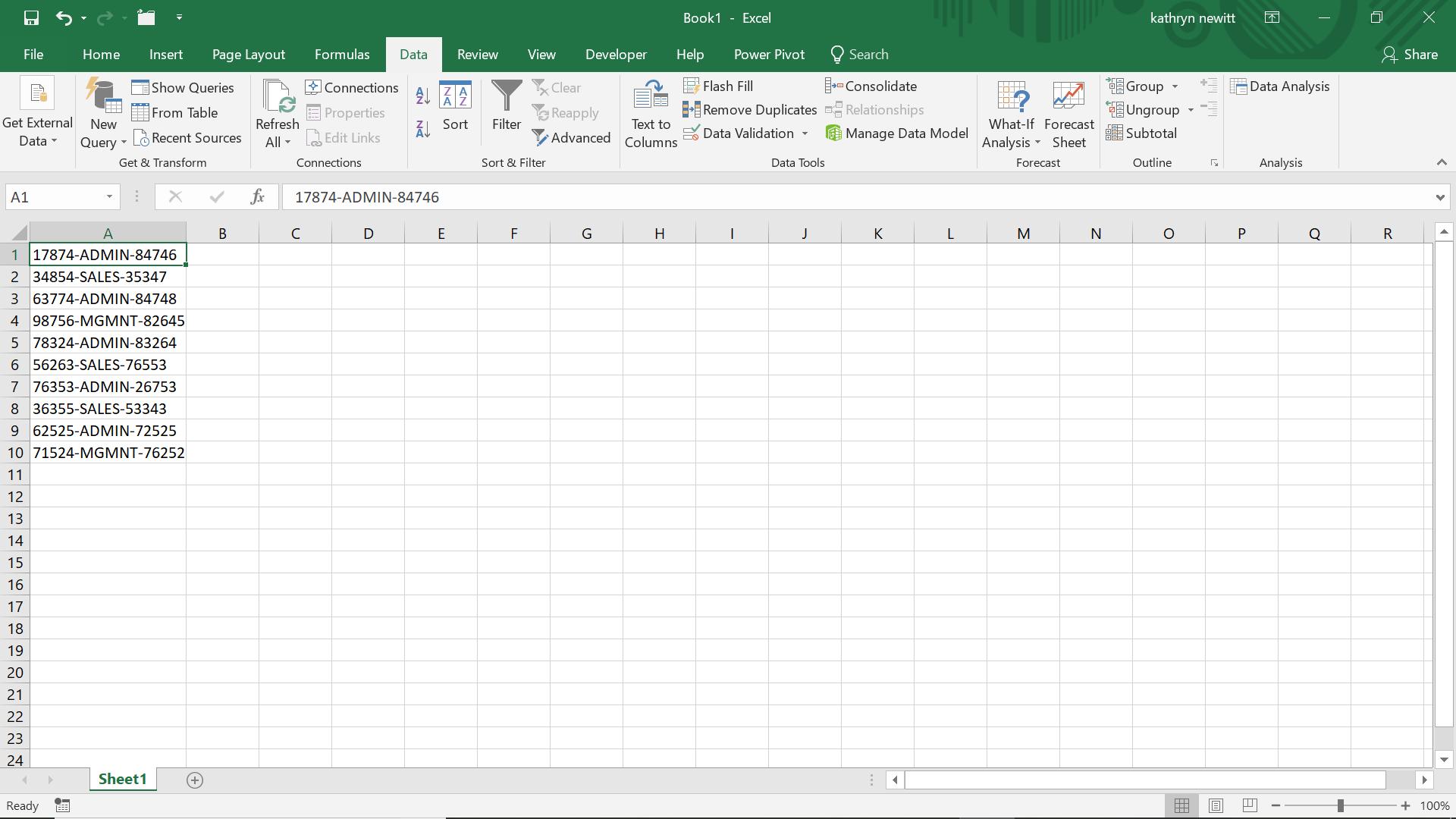
This function can be used to extract a consecutive portion of a text string. This is particularly useful for extracting information from references; for example, the department from a product ID. The following screen shows some references that I am going to extract the department from:
I use the ‘From Table’ option on the ‘Get and Transform’ section of the ‘Data’ tab. I can now use the Text.Middle() formula to extract a new column from my original data.
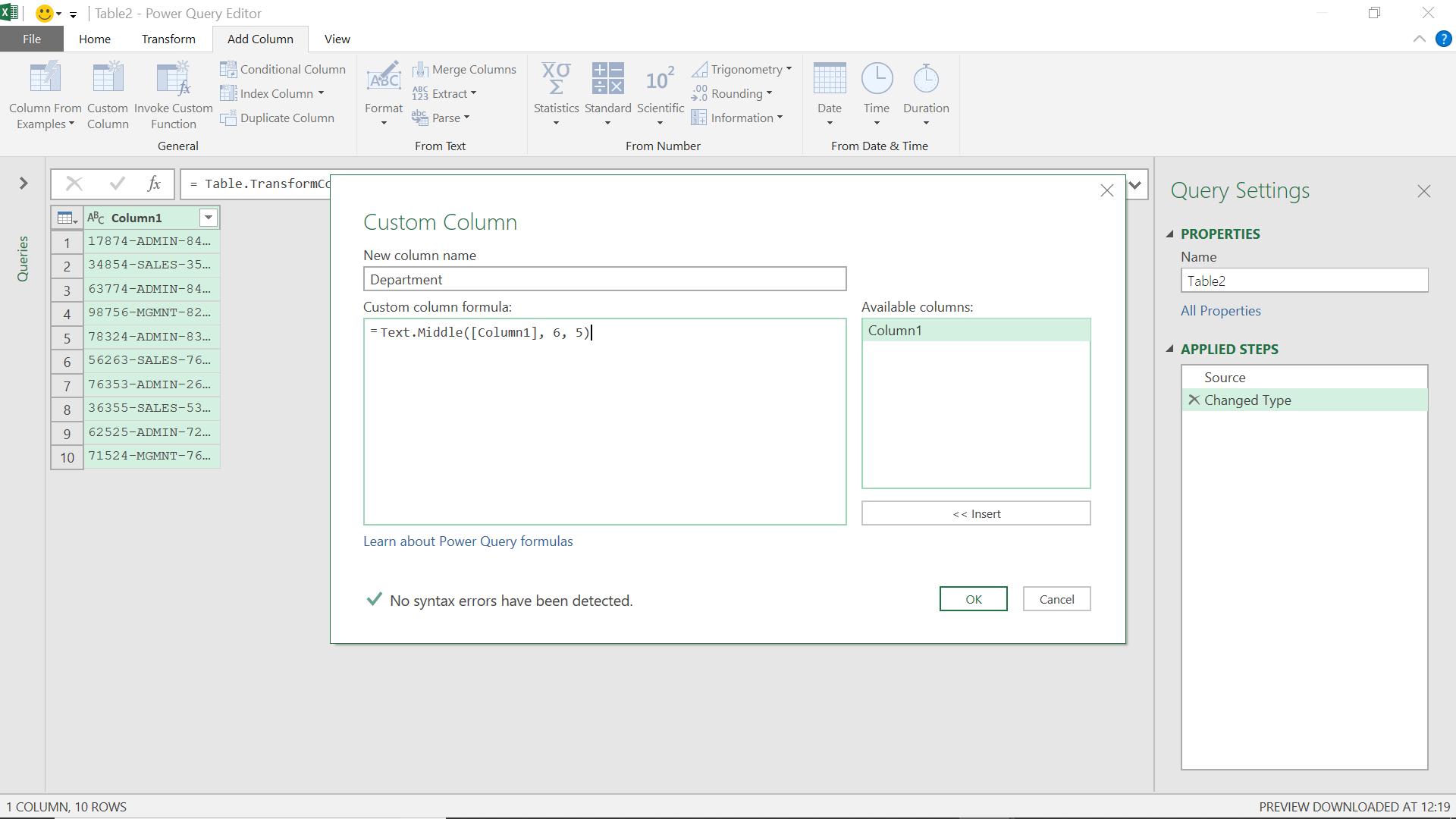
The M formula I have used is
= Text.Middle([Column1], 6, 5)
This tells Power Query to start at position six (6) (counting from position 0) and select the next five characters.
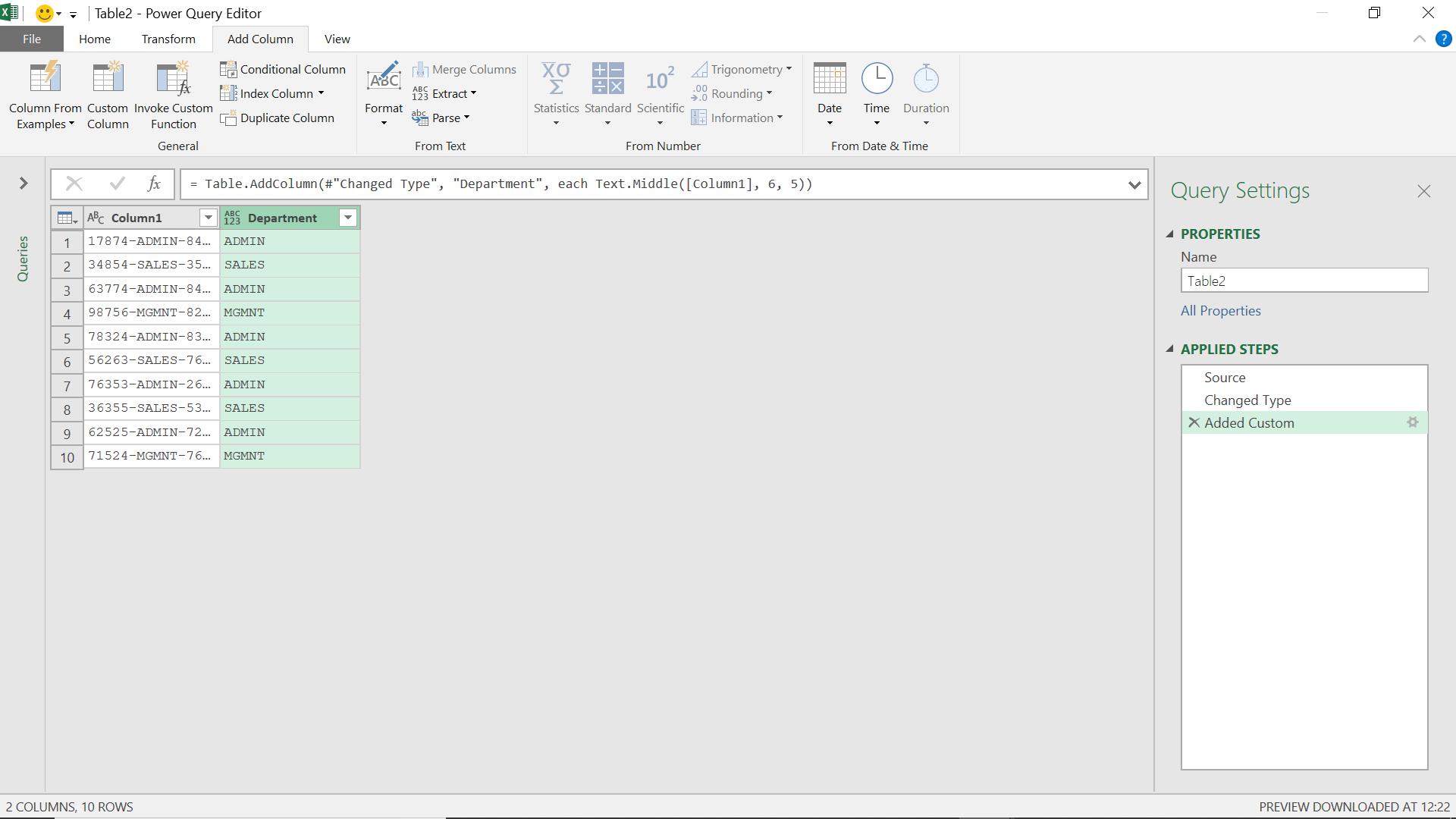
This selects the department, and I can link to other data which uses the same department codes.
Text.AfterDelimiter
Text.AfterDelimiter(text as nullable text, delimiter as text, optional index as any) as any
Returns the portion of text after the specified delimiter. An optional numeric index indicates which occurrence of the delimiter should be considered.
I can use this function to extract the second serial number from the product ID.
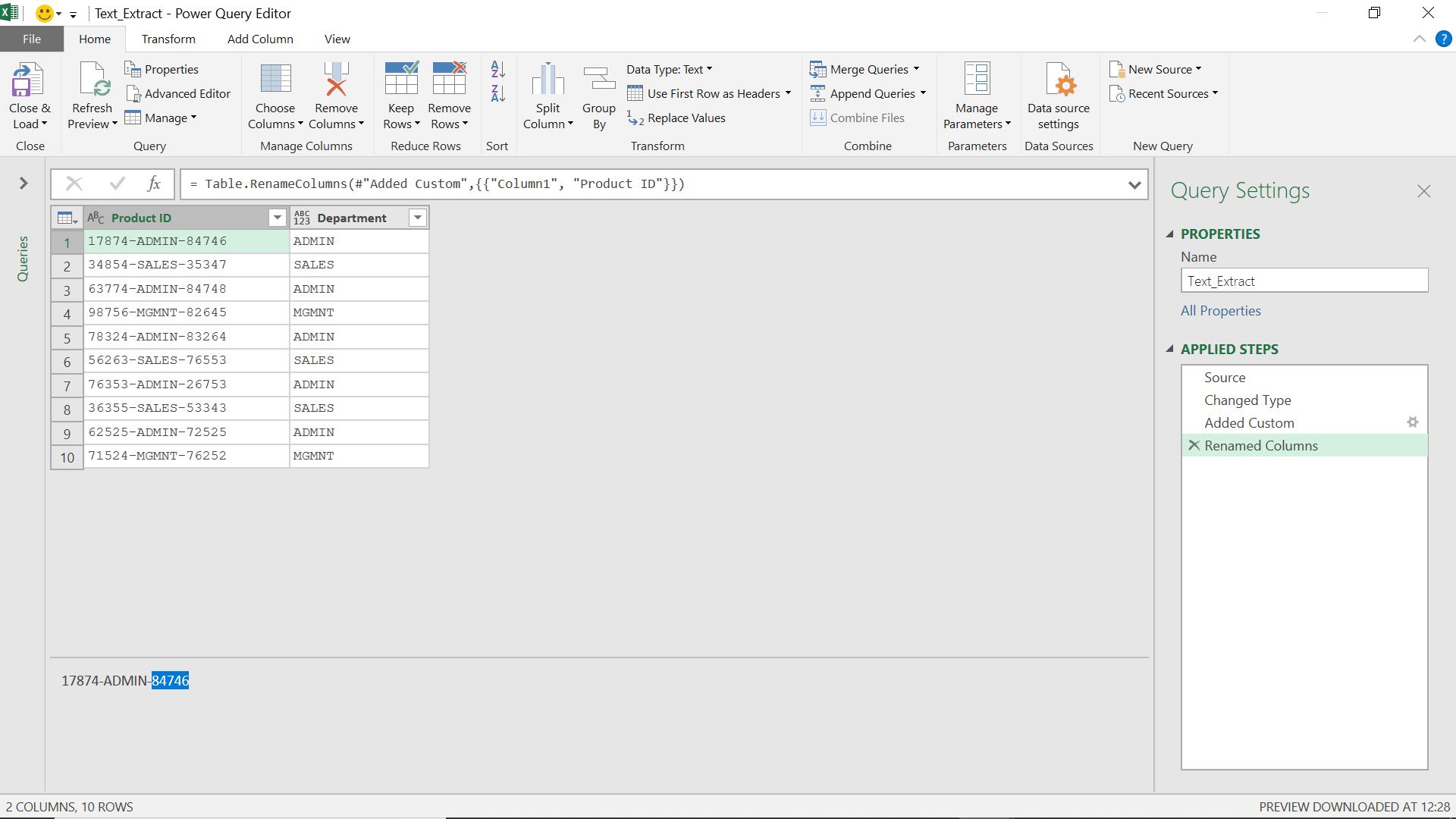
I create a new column using Text.AfterDelimiter():
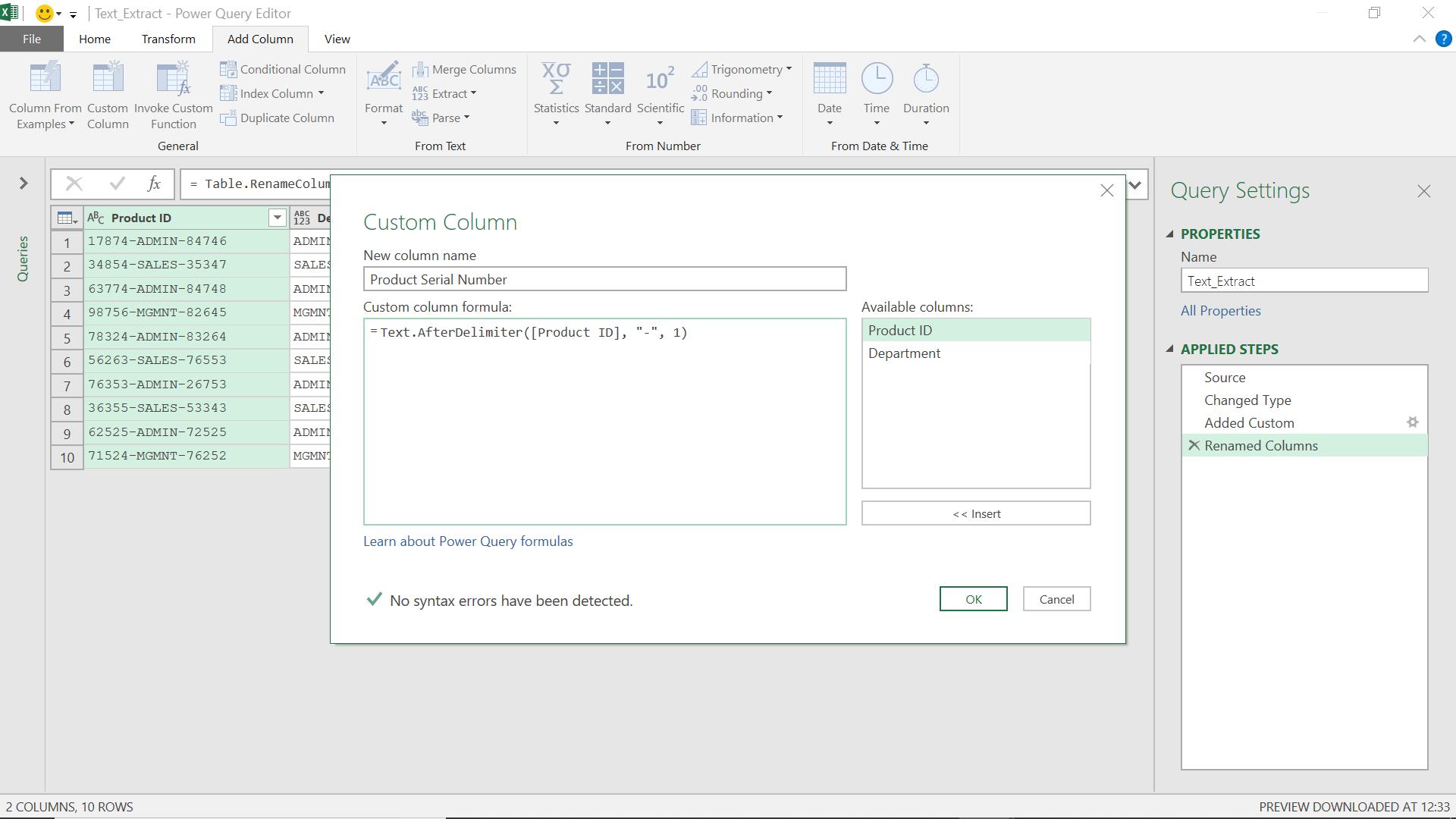
My M formula is
= Text.AfterDelimiter([Product ID],"-", 1)
This means, select what comes after the second occurrence of “-“ (since the first occurrence is counted as 0).
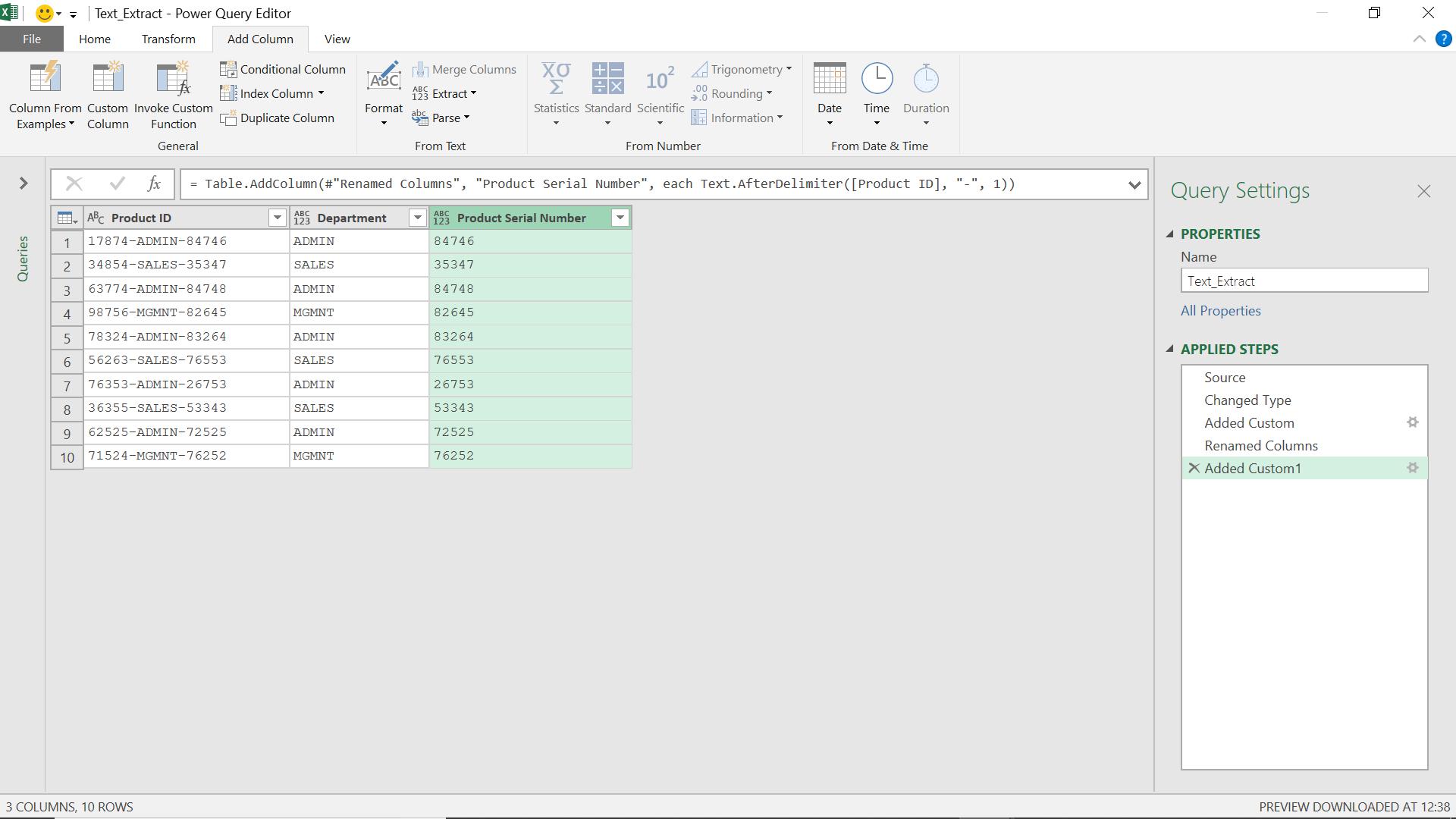
I have my serial number. In order to get the first number, the nominal code, I will need another function, which is coming up next.
Text.BeforeDelimiter
Text.BeforeDelimiter(text as nullable text, delimiter as text, optional index as any) as any
Returns the portion of text before the specified delimiter. An optional numeric index indicates which occurrence of the delimiter should be considered.
It’s very similar to the previous function: this time I get the text before the delimiter.
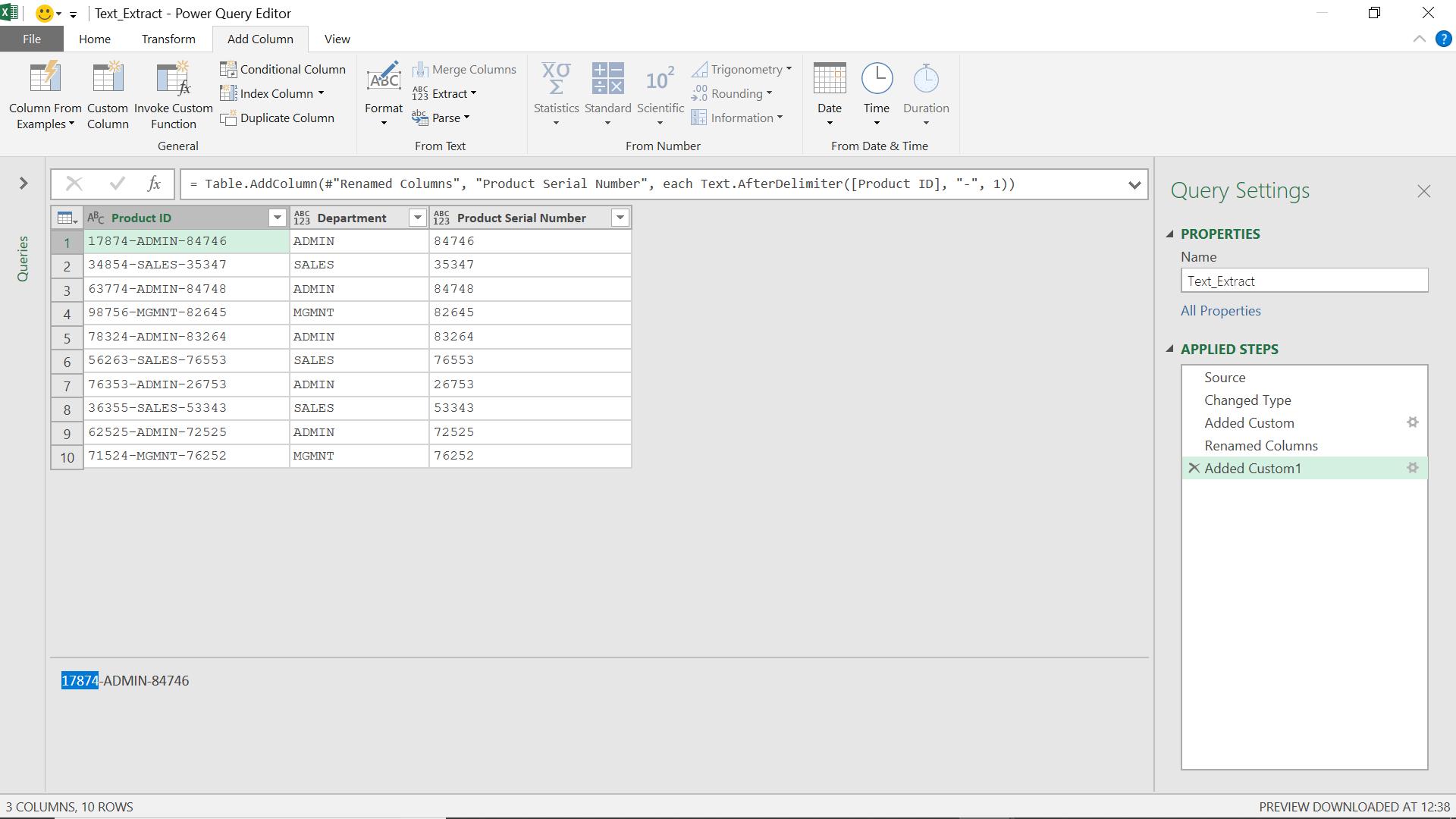
I add a column that uses the M function Text.BeforeDelimiter().
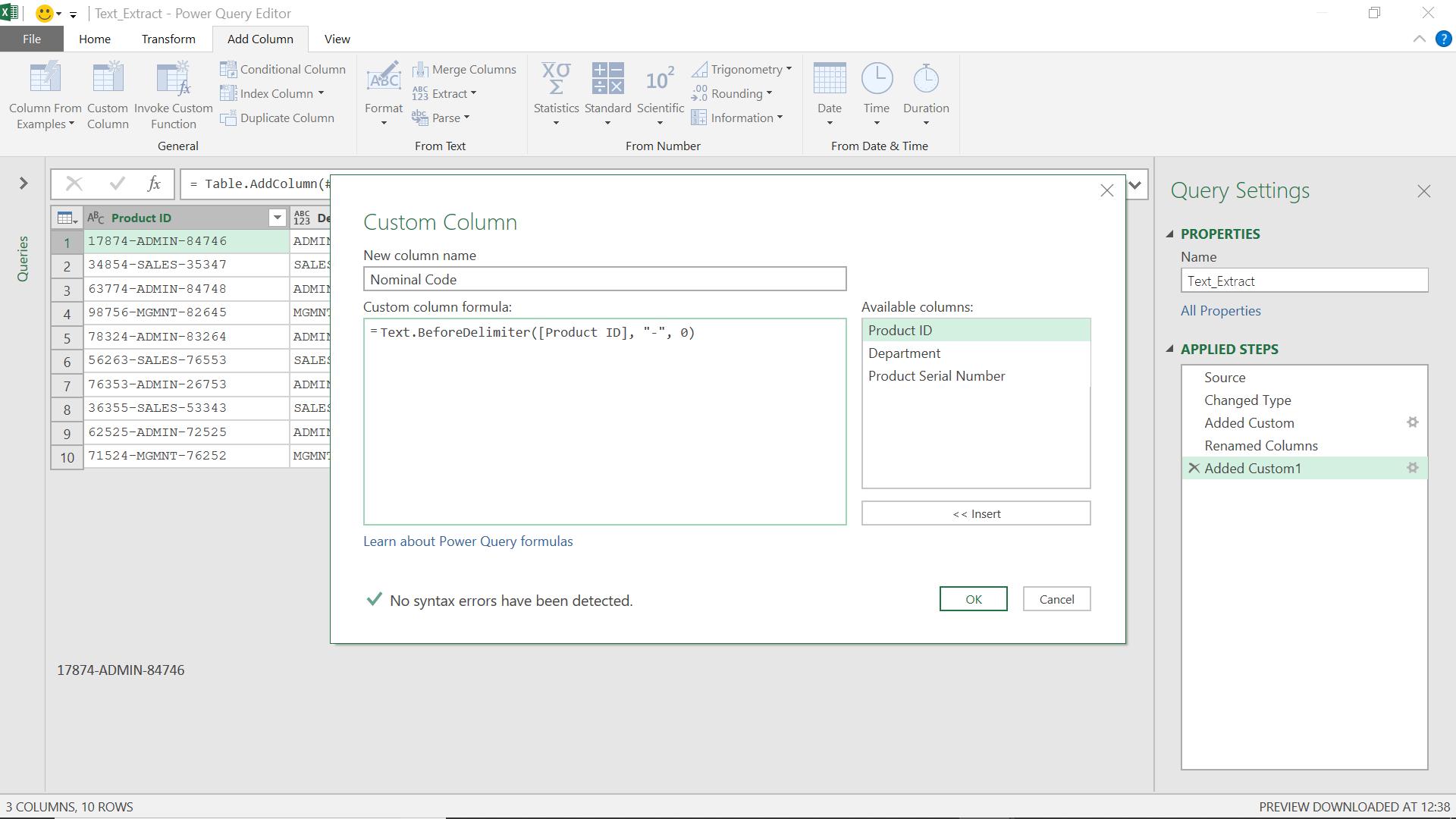
The M formula I use is
= Text.BeforeDelimiter([Product ID], "-", 0)
This tells Power Query to get the text before the first occurrence of “-“ (the first occurrence is counted as 0)
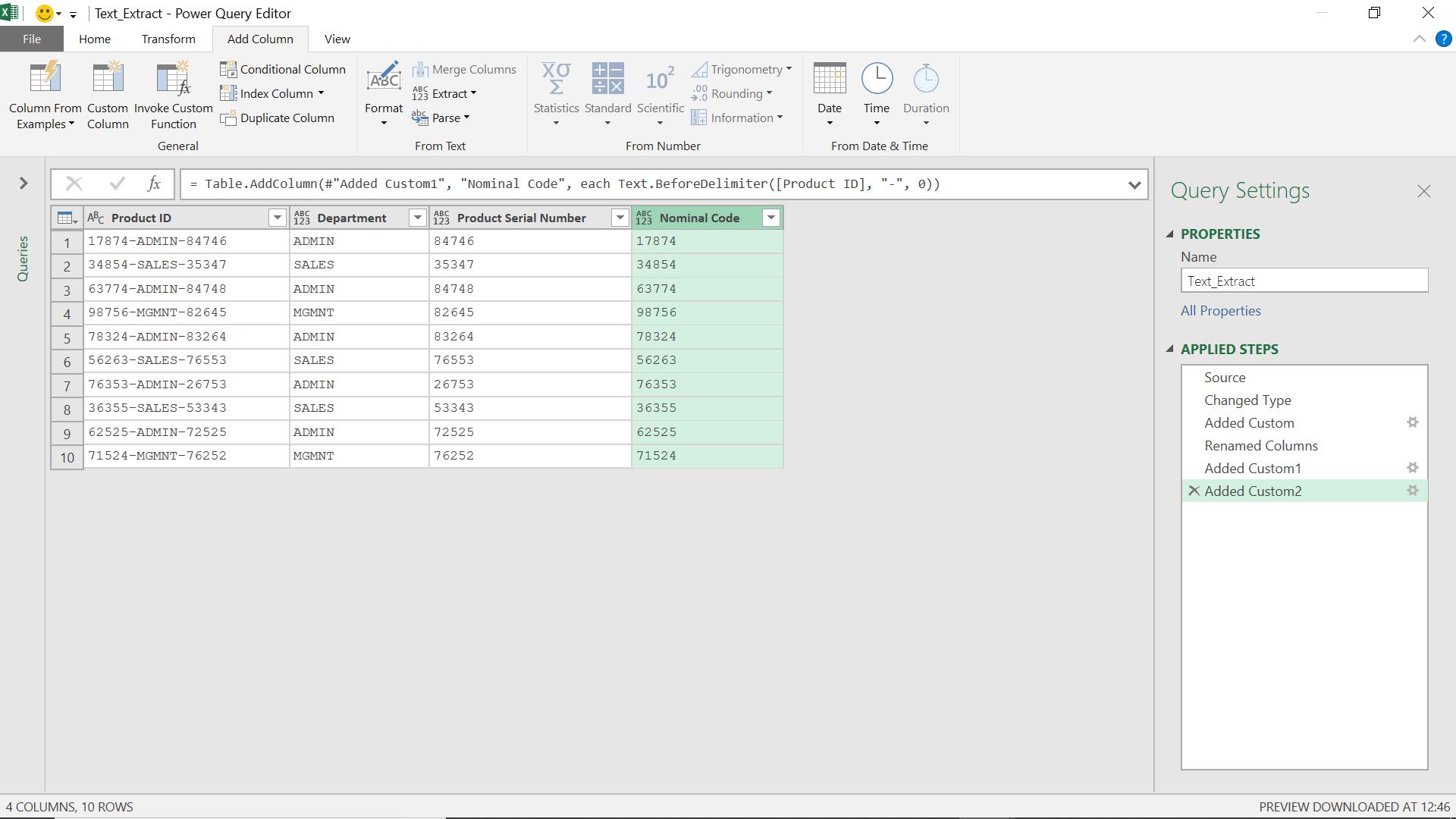
I have now extracted useful columns from the product ID. The Text.AfterDelimiter() and Text.BeforeDelimiter() functions do not rely on the length of the product ID segments being consistent, whereas the Text.Middle() function does. There is a way to extract the department which does not assume it always occurs at the same position in the text – and that function is coming next.
Text.BetweenDelimiters
Text.BetweenDelimiters(text as nullable text, startDelimiter as text,endDelimiter as text, optional startIndex as any, optional endIndex as any) as any
Returns the portion of text between the specified startDelimiter and endDelimiter. An optional numeric startIndex indicates which occurrence of the startDelimiter should be considered and an optional numeric endIndex indicates which occurrence of the endDelimiter should be considered.
This is much more flexible than I need it to be in my example, because my delimiters are the same. This function would allow me to get the text between two different delimiters, e.g. “-“ and “;”, and specify the occurrence of each one. The occurrence for the startDelimiter is from the beginning, and the occurrence of the endDelimiter is from the end. I can use this function to get the department, even if it is longer than the standard five characters I have used. I’ve added a new reference code to demonstrate.
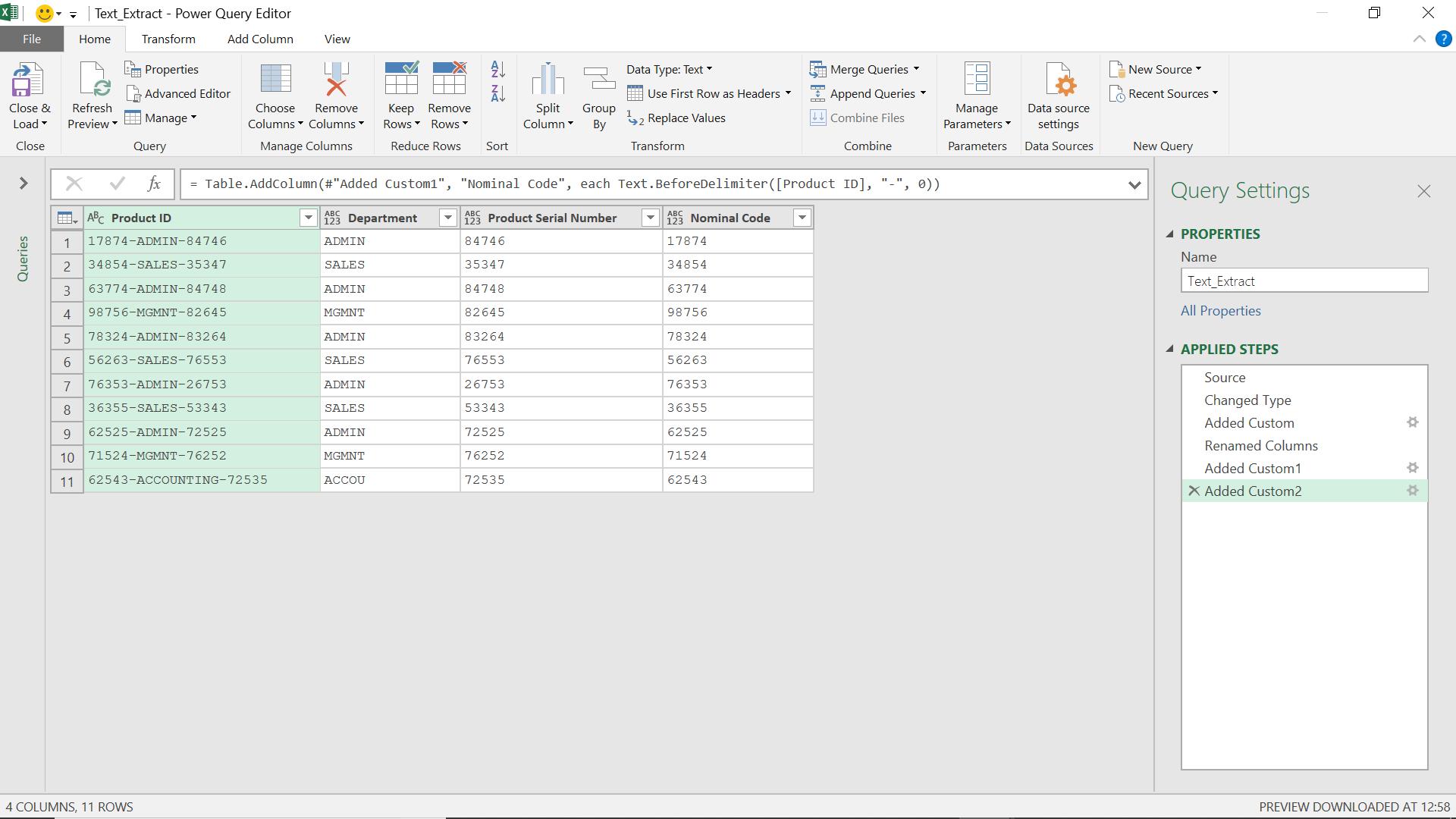
I use Text.BetweenDelimiters() to create a new column.
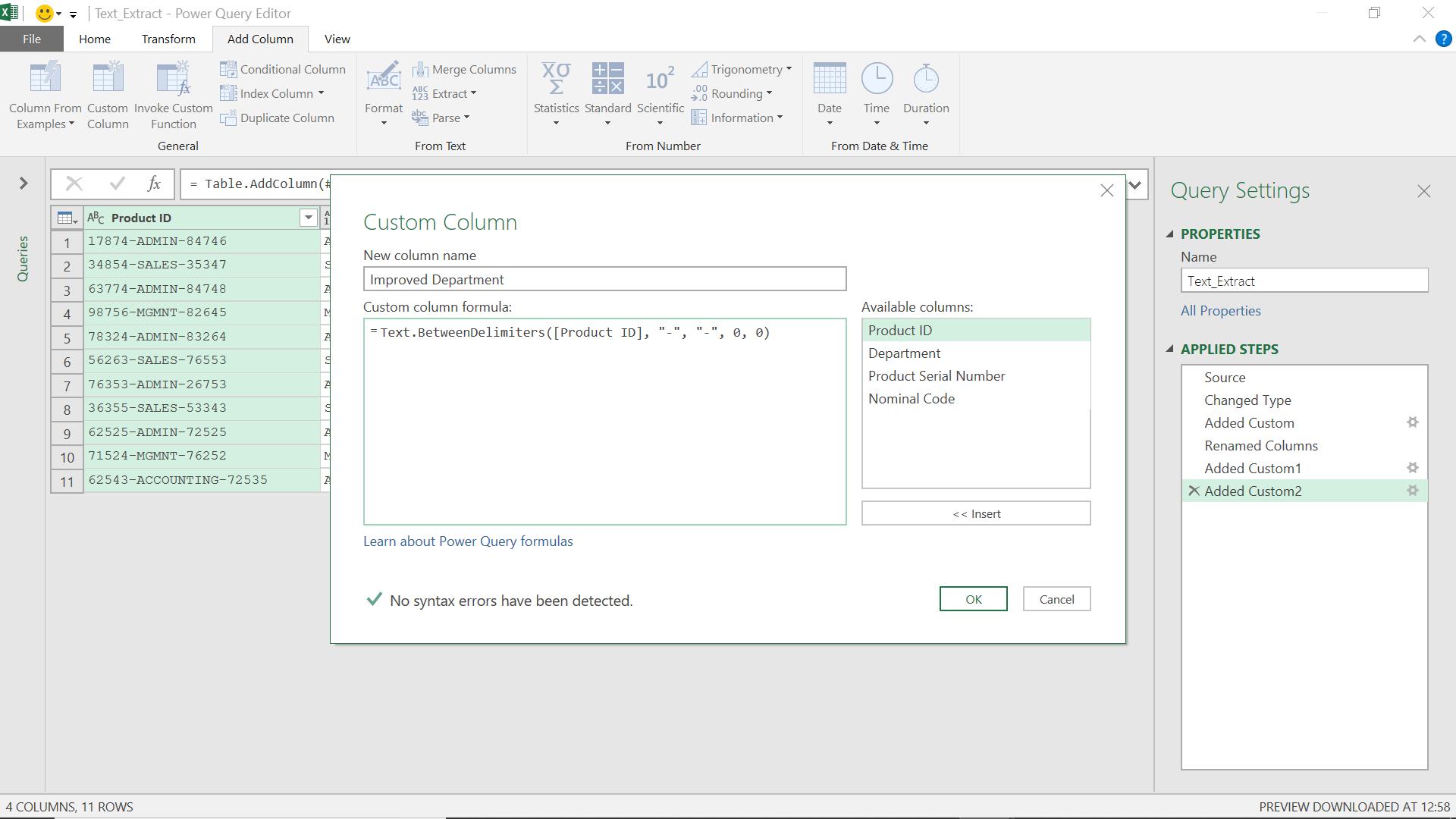
The M formula I have used is
= Text.BetweenDelimiters([Product ID], "-", "-", 0, 0)
This will give me the text between the first “-“ (count 0 from the beginning) and the second “-“ (count 0 from the end).
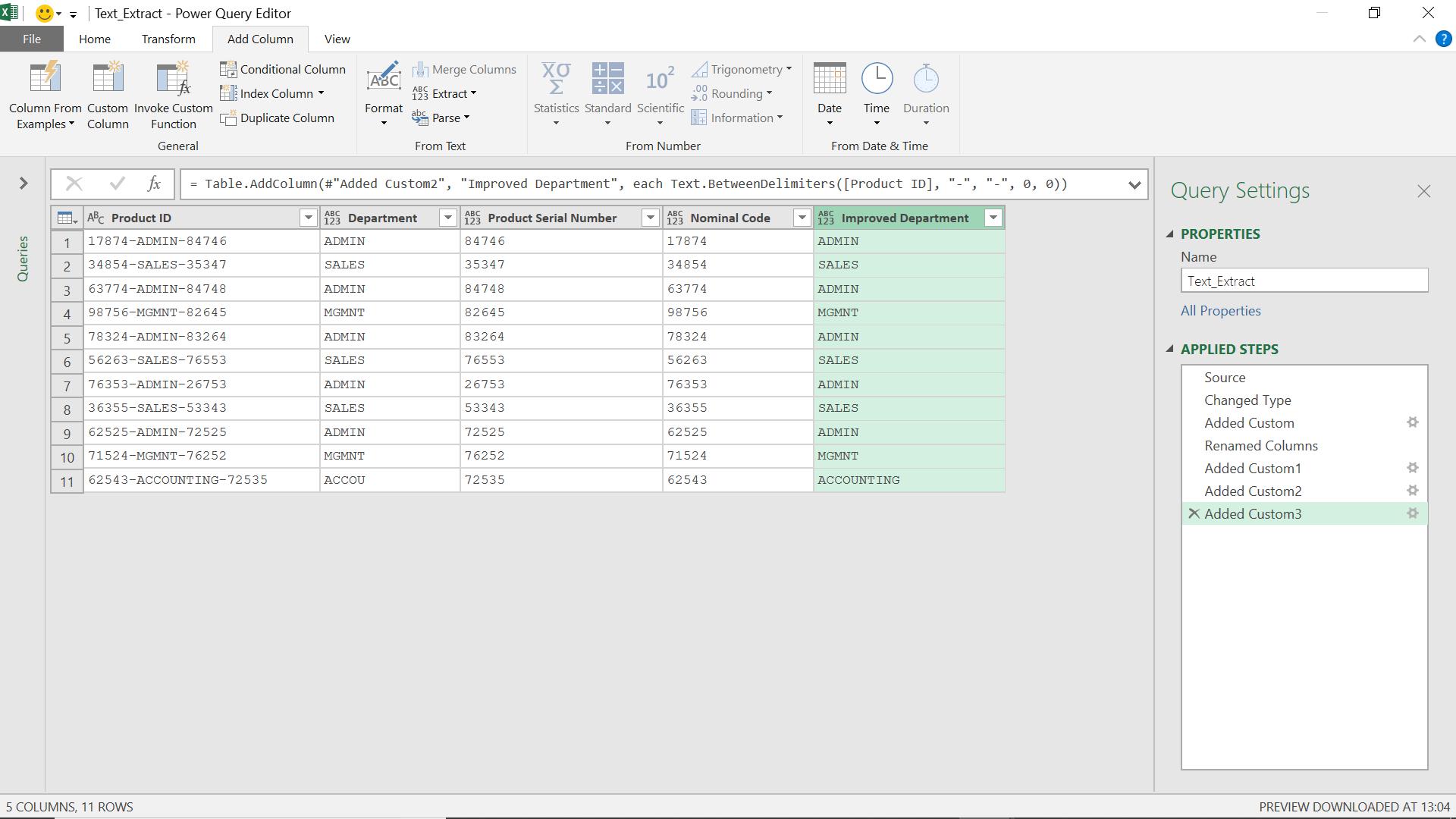
I have all three of my segments extracted to separate columns so that I can analyse my data further.
Come back next time for more ways to use Power Query!