
New Regex Modes for XLOOKUP and XMATCH
14 August 2024
As we have explained previously, the term “regex” is an abbreviation of “regular expressions” and is a language used for pattern-matching text content. It is frequently implemented in various programming languages such as C, C++, Java, Python, VBScript – and of course, that latest and greatest software, Excel!
Microsoft has stated that the version of Regex coming to Excel uses a “flavor” (sic) called PCRE2 (PHP>=7.3) for those that need to know the underlying technical stuff.
To use this fully, you need to understand the syntax for regular expressions. Here is a crash course table, which summarises some – but not all – of the main elements, usually referred to as “tokens”.
| Token | Meaning |
|---|---|
| \ | This converts special characters (metacharacters) to literal characters, and also allows the literal matching of the regex delimiter in use, e.g. ‘/’ |
| . | Matches any character other than newline |
| ^ | Matches the start of string without consuming any characters. If multiline mode is used, this will also match immediately after a newline character |
| $ | Matches the end of string without consuming any characters. If multiline mode is used, this will also match immediately before a newline character |
| a? | Matches zero [0] or one [1] of a. This matches an ‘a’ character or nothing |
| a* | Matches zero [0] or more of a. This matches zero or consecutive ‘a’ characters |
| a+ | Matches one [1] or more of a. This matches consecutive ‘a’ characters |
| a{4} | Matches exactly four [4] instances of ‘a’ |
| a{4,} | Matches four [4] or more instances of ‘a’ |
| a{4,6} | Matches between four [4] and six [6] instances of ‘a’ |
| \A | Matches the start of a string only. Unlike ^, this is not affected by multiline mode |
| \Z | Matches the end of a string only. Unlike $, this is not affected by multiline mode |
| \z | Matches the absolute end of a string only. Unlike $, this is not affected by multiline mode and in contrast to \Z, this will not match before a trailing newline at the end of a string |
| \b | Matches a word boundary. It matches without consuming any characters, immediately between a character matched by \w and a character not matched by \w. It cannot be used to separate non-words from words |
| \B | Matches a non-word boundary. It matches without consuming any characters , at the position between two characters matched by \w or \W |
| I | A case insensitive match is performed |
| X | Ignore whitespace / verbose. This flag instructs the engine to ignore all whitespace and allow for comments in the regex, also known as verbose. Comments are indicated by starting with the # character and then escaping with \ |
| xx | Ignore all whitespace / verbose. Similar to x, but whitespace is also ignored inside of character classes |
| s | Known as single line, this enables the dot (.) metacharacter to also match newlines, thus treating the whole string as a single line input |
| \n | Matches a newline character |
| \N | Matches anything other than a newline character |
| \r | Matches a carriage return, Unicode character U+2185 |
| \R | Careful! Matches any Unicode newline sequence |
| \t | Matches a tab character (typically, tab stops happen every eight [8] characters) |
| \0 [zero] | Matches a null character, Unicode character U+2400 |
| \d | Matches any decimal / digit. Equivalent to [0-9] |
| \D | Matches anything other than a decimal / digit |
| \s | Matches any whitespace character (space, tab or newline) |
| \S | Matches any non-whitespace character (anything other than space, tab or newline) |
| \w | Matches any word character (any letter, digit or underscore). Equivalent to [a-zA-Z0-9_] |
| \W | Matches any non-word character (anything other than a letter, digit or underscore). Equivalent to [^a-zA-Z0-9_] |
| [abc] | Matches an ‘a’, ‘b’ or ‘c’ character |
| [^abc] | Matches any character except ‘a’, ‘b’ or ‘c’ |
| a|b | Alternate match: matches what is before or after |, in this case ‘a’ or ‘b’ |
| [a-z] | Matches any characters between a and z inclusive |
| [^a-z] | Matches any characters, except those in the range a to z inclusive |
| [a-zA-Z] | Matches any characters between a to z or A to Z inclusive |
| [[:alnum:]] | Double square brackets are required here. Matches letters and digits. This is equivalent to [A-Za-z0-9] |
| [[:alpha:]] | Matches letters. Equivalent to [a-zA-Z] |
| [[:ascii:]] | Matches any character in the valid ASCII range (any basic Latin character). ASCII codes 0 to 127 inclusive |
| [[:blank:]] | Matches spaces and tabs (but not newlines). Equivalent to [ \t] |
| [[:cntrl:]] | Matches characters that are often used to control text presentation, including newlines, null characters, tabs and the escape character |
| [[:digit:]] | Matches decimal / digits. Equivalent to [0-9] or \d |
| [[:graph:]] | Matches visible characters (not space: printable, non-whitespace, non-control characters only) |
| [[:lower:]] | Matches lowercase letters. Equivalent to [a-z] |
| [[:print:]] | Matches printable characters, part of the basic Latin set, such as letters and spaces, but not including control characters |
| [[:punct:]] | Matches visible punctuation characters that are not whitespace, letters or numbers |
| [[:space:]] | Matches whitespace characters. Equivalent to \s |
| [[:upper:]] | Matches uppercase letters. Equivalent to [A-Z] |
| [[:word:]] | Matches word characters (letters, numbers and underscores). Equivalent to \w or [a-zA-Z0-9_] |
| [[:<:]] | Matches the start of word |
| [[:>:]] | Matches the end of word |
| (?:…) | Match everything enclosed. For example, repeating 1-3 digits and a period 3 times can be identified as follows: /(?:\d{1,3}\.){3}\d{1,3}/ |
| (…} | Capture everything enclosed |
Now that I have provided a refresher, regular expressions are starting to infiltrate Excel. It began with three new functions:
REGEXEXTRACT(text, pattern, [return_mode], [ignore_case])
REGEXREPLACE(text, pattern, replacement, [occurrence], [ignore_case])
REGEXTEST(text, pattern, [ignore_case]).
However, now you may take further advantage of regex within the existing XLOOKUP and XMATCH functions, by using the new match_mode= 3 and a regex pattern as the lookup_value.
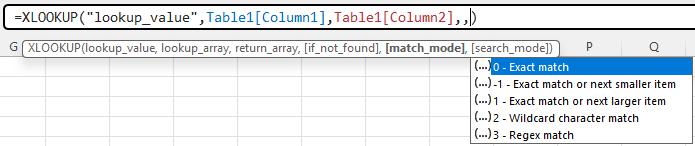
This will allow XLOOKUP and XMATCH to match against parts of text in a cell, or by any other pattern of text that can be described with regex.
Here is one example we’ve all been desperate for: fuzzy matching, i.e. a search technique used to identify similar text strings, such as looking for a reference to Australia, such as “Aussie”, “Australia” or “Oz”.
Consider the following Table of data called Country_Sales_Data:
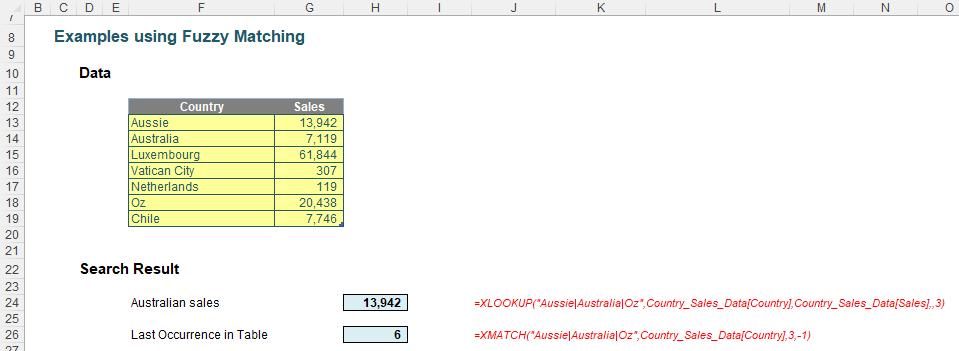
Here, I have created a formula in cell H24 which has determined the sales for the first record that contains an aforementioned reference to Australia:
=XLOOKUP("Aussie|Australia|Oz",Country_Sales_Data[Country],Country_Sales_Data[Sales],,3)
Note that the fifth argument (match_mode) is three [3], which is the new Regex match.
"Aussie|Australia|Oz" is the regular expression (in quotation marks) that provides alternate matches (see above Regex tokens table). It does not matter which order these three alternatives are cited: XLOOKUP will seek out the first match, which in this case is the very first record.
XMATCH works similarly in cell H26, viz.
=XMATCH("Aussie|Australia|Oz",Country_Sales_Data[Country],3,-1)
Again, note that the third argument (match_mode) is three [3], which is the new Regex match. The fourth argument (search_mode) is -1 here, so that XMATCH searches last to first.
This is great, but I am not keen on hard code, so it got me thinking: how about I create a table of date for all my fuzzy match acceptable alternatives? Well, that’s precisely what I did:
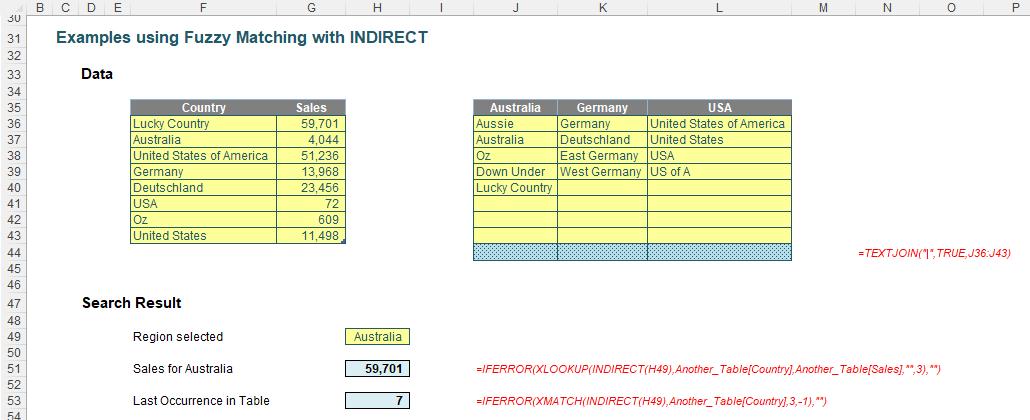
There is a new Table here called Another_Table (I’m nothing if not unimaginative). Then, in cells J35:L43, I have provided an input data table for alternative names for the countries Australia, Germany and USA. In the shaded cells J44:L44, I have created three hidden formulae. For example, the formula in cell J44 is
=TEXTJOIN("|",TRUE,J36:J43)
This uses the TEXTJOIN function to create a text string of all non-blank values in the range J36:J43 separating them with | and ignoring blanks. This provides the albeit hidden result:
Aussie|Australia|Oz|Down Under|Lucky Country
Each of these three cells has been given a range name: Australia (cell J44), Germany (cell K44) and USA (cell L44). I have then created a drop-down data validation list (ALT + D + L or Data -> Data Validation from the Ribbon):

The INDIRECT function is then employed in the corresponding XLOOKUP and XMATCH functions. INDIRECT allows the creation of a formula by referring to the contents of a cell, rather than the cell reference itself.
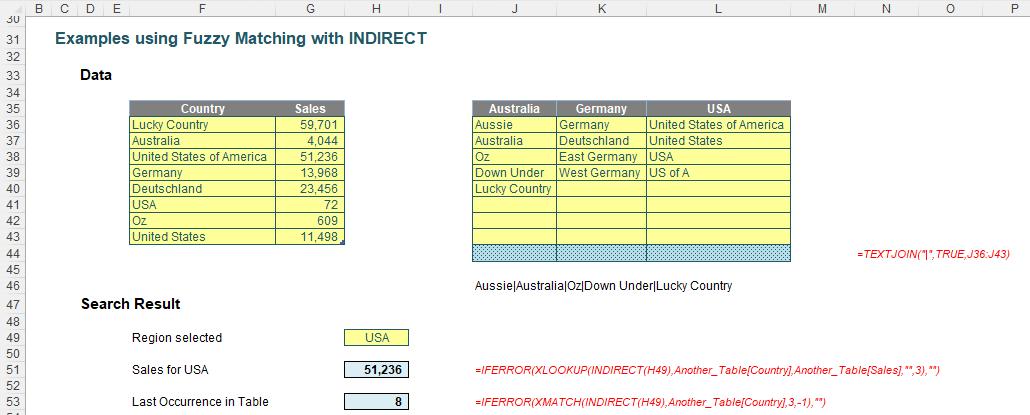
The sales figure in cell H51 is calculated as
=IFERROR(XLOOKUP(INDIRECT(H49),Another_Table[Country],Another_Table[Sales],"",3),"")
Similarly, the final occurrence formula in cell H53 is given by
=IFERROR(XMATCH(INDIRECT(H49),Another_Table[Country],3,-1),"")
This means that I can switch the country without having to revise the Regex code:
Some people aren’t keen on INDIRECT as it is both volatile (i.e. it recalculates whenever something changes in the file) and is non-auditable (i.e. it “fools” Excel’s built-in audit tools). Therefore, an alternative (using Yet_Another_Table as the Table data source) would be the following:
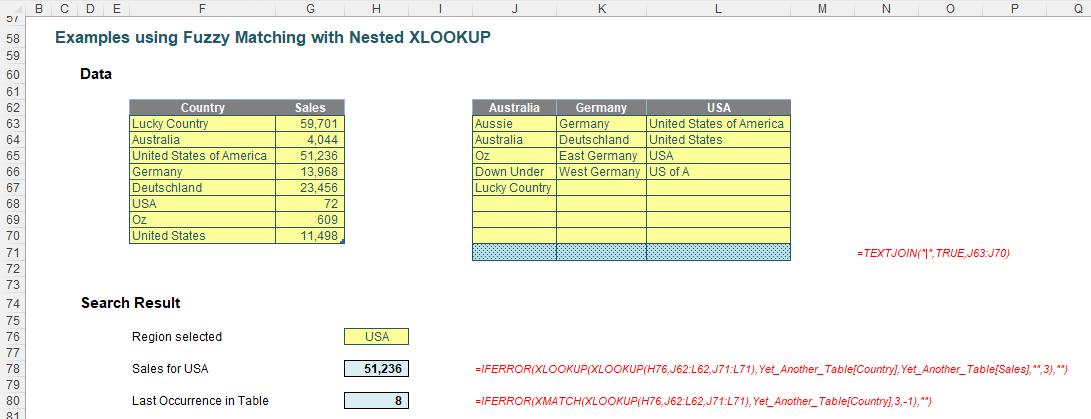
Here, we swap out the lookup_value in both the XLOOKUP and XMATCH functions which uses INDIRECT for a “nested” XLOOKUP expression instead. Thus, cell H78 contains the formula
=IFERROR(XLOOKUP(XLOOKUP(H76,J62:L62,J71:L71),
Yet_Another_Table[Country],Yet_Another_Table[Sales],"",3),"")
and cell H80 contains the revised formula
=IFERROR(XMATCH(XLOOKUP(H76,J62:L62,J71:L71),Yet_Another_Table[Country],3,-1),"")
Of course, fuzzy matching is just one use of the new features in XLOOKUP and XMATCH. I can go hunting for text strings that include inadvertent non-numerical values. For example, consider the data Table called Data:
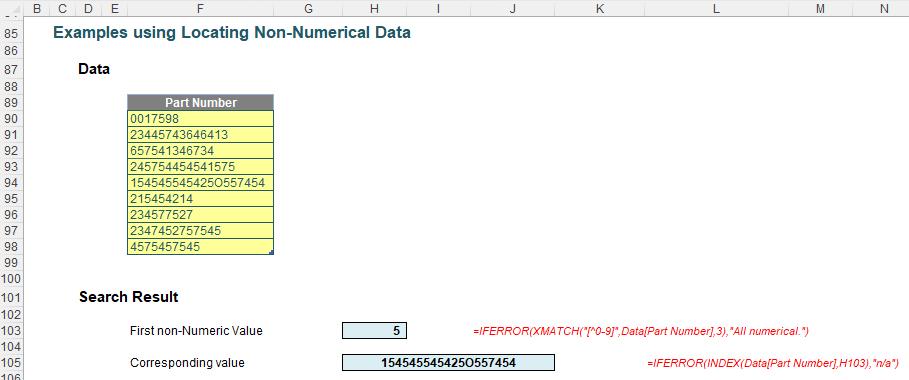
Here, the formula in cell H103 identifies the first record that contains a non-numerical value:
=IFERROR(XMATCH("[^0-9]",Data[Part Number],3),"All numerical.")
[^0-9] simply means find something that is not the numbers zero [0] to nine [9]. Once this has been located, I can then use the INDEX function to identify it in cell H105:
=IFERROR(INDEX(Data[Part Number],H103),"n/a")
I have made the non-numerical value deliberately difficult to spot:
154545545425O557454
That’s right: that is the capital letter O, not a zero [0]! It didn’t fool Excel.
Of course, you can get more complex:

Here, for the Table Text_Data, I have used the formula
=IFERROR(XMATCH("(\w*([a-zA-Z])\2\w*)",Text_Data[Text],3),"No instances.")
in cell H128. Take my word for it, but the expression ,
(\w*([a-zA-Z])\2\w*)
seeks out any text string that contains adjacent repeated letters that are either both lower case or both upper case (hence “apPle” is not recognised but “Cheese” is). Try it for yourself; I am sure you can construct even more complex monstrosities!
You can check out all of the above examples in the attached Excel file.
Word to the Wise
Of course, you will all whinge at me when you discover you don’t have this feature – yet. These new function modes are in Preview only presently. Their results may change substantially before being widely released, based upon Insider Beta users’ feedback. Thus, I do not recommend using these functions in important workbooks until they become Generally Available.
Presently, these functions are rolling out to Beta Channel users running:
- Windows: Version 2408 (Build 17931.20000)
- Mac: Version 16.89 (Build 24080715).
Don’t let it deter you though!